

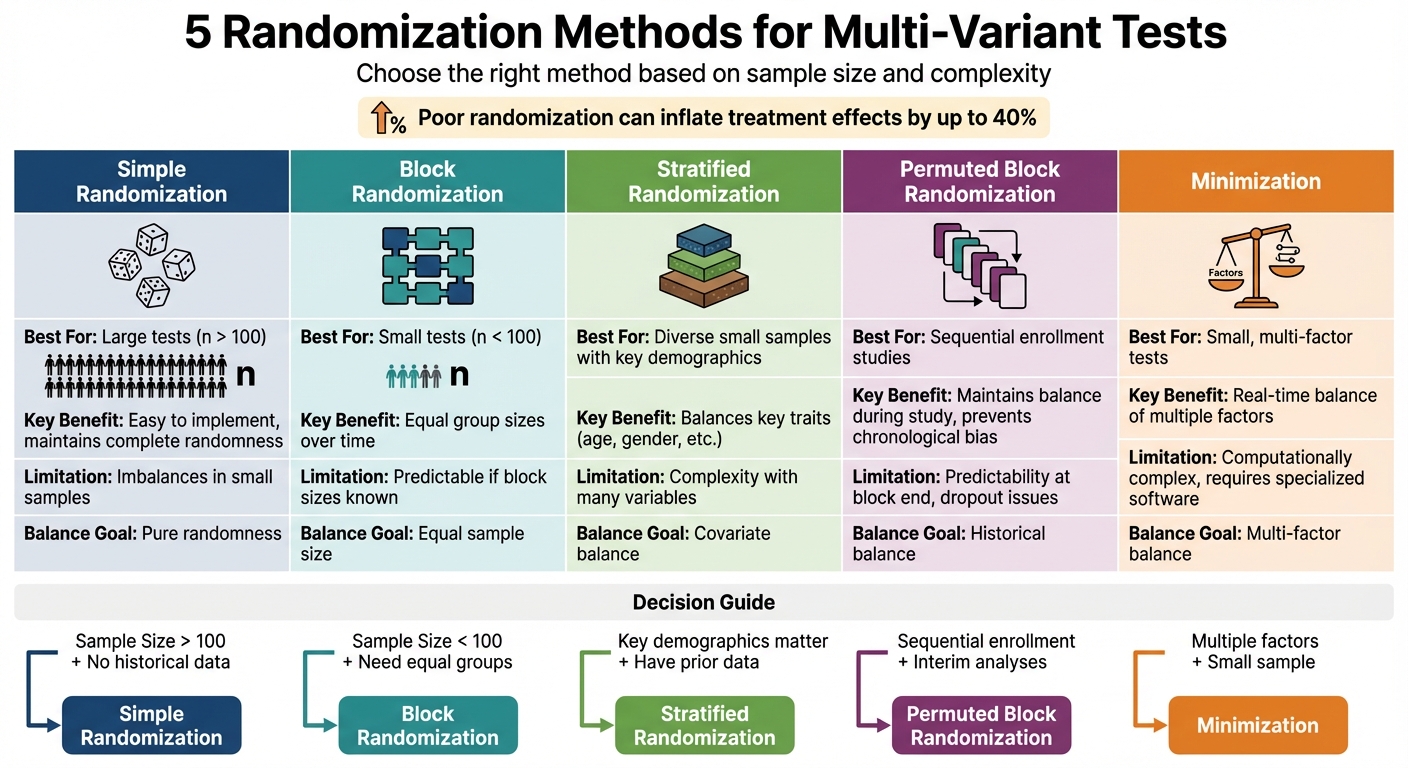
Multi-variant testing (MVT) is a powerful approach to optimize performance by testing multiple variables simultaneously, such as headlines, images, or button colors. However, the success of MVT heavily depends on proper randomization to ensure reliable results. Poor randomization can lead to skewed data, exaggerated effects (up to 40%), and costly mistakes. Here are five key randomization methods you can use:
- Simple Randomization: Assigns participants randomly to groups. Best for large tests (over 100 participants) but may cause imbalances in smaller samples.
- Block Randomization: Ensures equal group sizes by dividing participants into blocks. Ideal for smaller tests but can be predictable if block sizes are known.
- Stratified Randomization: Balances key traits (e.g., age, gender) across groups. Great for smaller, diverse samples but adds complexity.
- Permuted Block Randomization: Maintains balance within each block and prevents chronological bias. Useful for sequential enrollment but requires confidential block sizes.
- Minimization: Actively balances groups by key factors in real-time. Effective for small samples but computationally intensive.
Quick Tip: Choose a method based on your sample size and available data. For large tests, simple randomization works well. For smaller or more complex tests, consider block, stratified, or minimization methods.
Quick Comparison
| Method | Best For | Key Benefit | Limitation |
|---|---|---|---|
| Simple Randomization | Large tests (n > 100) | Easy to implement | Imbalances in small samples |
| Block Randomization | Small tests (n < 100) | Equal group sizes | Predictable if block sizes known |
| Stratified Randomization | Diverse small samples | Balances key traits | Complexity with many variables |
| Permuted Block Randomization | Sequential enrollment | Maintains balance during study | Predictability, dropout issues |
| Minimization | Small, multi-factor tests | Real-time balance of key factors | Computationally complex |
Proper randomization ensures valid results, reduces bias, and helps isolate the true effects of your changes. Use the method that aligns with your test’s size and complexity.
Comparison of 5 Randomization Methods for Multi-Variant Testing
Multivariate Testing: Test Multiple Variables Simultaneously | Advanced Product Experimentation
sbb-itb-2ec70df
1. Simple Randomization
Simple randomization is the easiest way to assign users to different variants in a multi-variant test. It works by giving each user an independent, random chance of being assigned to any variant. As the EGAP Methods Guide puts it:
"The simplest [way to randomize] is to flip a coin each time you want to determine whether a given subject gets treatment or not. This ensures that each subject has a .5 probability of receiving the treatment and a .5 probability of not receiving it."
The main advantage here is that each assignment happens independently. For consistency and replicability, you can use computer-generated random numbers from tools like R or SAS. But while it’s straightforward, this method isn’t without its challenges.
Best Use Case
Simple randomization works best in experiments with over 100 participants. In larger groups, random fluctuations tend to even out, making the results more reliable. It’s also a great choice when testing on new users, especially if you don’t have historical data to guide you. As Allon Korem and Oryah Lancry-Dayan from Statsig explain:
"The idea behind simple randomization is straightforward: if you randomly select users and assign them to groups, the groups will likely have a similar mix of characteristics."
That said, simplicity can sometimes come at a cost.
Limitations
One downside is that group sizes can end up uneven, which can be a problem in smaller trials with fewer than 100 participants. Another issue is the potential for covariate imbalance – where one group might end up with a disproportionate share of certain user characteristics, potentially skewing the results. For smaller experiments, these imbalances can make it harder to trust your findings.
Simple randomization is a foundational method, setting the stage for more advanced techniques discussed in upcoming sections.
2. Block Randomization
Block randomization is a method used to divide participants into blocks, ensuring equal sample sizes across different treatment groups. KP Suresh, a biostatistics expert, explains:
"The block randomization method is designed to randomize subjects into groups. This method is used to ensure a balance in sample size across groups over time."
This approach helps maintain balance in group sizes, which is especially important in complex multi-variable testing (MVT) designs, where imbalances can skew results.
To implement block randomization, you first determine a block size that is a multiple of the number of treatment groups. Within each block, all possible balanced permutations are calculated, and blocks are then randomly selected to create the assignment sequence. For example, in a two-variant test with a block size of 4, there are six possible balanced permutations.
Best Use Case
Block randomization shines in smaller to mid-sized experiments (fewer than 100 participants), where simple randomization might lead to uneven group sizes. It’s also effective when external factors – like age, gender, or time of day – could affect outcomes. For instance, CVS Health applied block randomization in a simulated marketing campaign to accurately measure treatment effects. [11, 12, 13]
While this method is highly effective in maintaining balance, it does come with some challenges.
Limitations
One key limitation is its potential predictability. If the block size is fixed and known, assignments within a block can become easy to guess. For example, with a block size of 2, once the first assignment is revealed, the second is entirely predictable. To address this, using variable block sizes – such as alternating randomly between blocks of 4, 6, and 8 – can help. Additionally, keeping block sizes confidential from site staff minimizes predictability. [7, 17] For unstratified trials, selecting block sizes greater than 15 can further reduce the risk of predictability.
Another challenge is the complexity of analyzing data from blocked designs. Many researchers opt for a simpler approach by ignoring the block structure during analysis, which can lead to conservative estimates.
3. Stratified Randomization
Stratified randomization divides participants into subgroups, or strata, based on specific characteristics like age, gender, or disease severity. Within each stratum, participants are then randomly assigned to treatment groups. Rohit Sharma, Head of Revenue & Programs at upGrad, explains:
"Stratified randomization is a method used to maintain the balance of clinical trial groups by key factors, such as age, disease stage, or risk levels."
This method focuses on balancing traits that could influence results, rather than just ensuring equal group sizes. By creating subgroups, it ensures that critical factors are evenly distributed across treatment groups, allowing for more balanced and reliable comparisons.
Balance Type
Stratified randomization does more than just equalize group sizes – it ensures that key participant traits are distributed evenly. Unlike simple randomization, which can occasionally lead to uneven distributions of important characteristics, this approach guarantees balance for variables that could significantly impact outcomes. This is especially useful for maintaining statistical power, as it ensures comparability between treatment arms. In fact, around 40% of large clinical trials adopt this method to minimize the risk of unintentional bias.
Best Use Case
This method is particularly effective when working with diverse populations where specific traits strongly influence outcomes. It’s especially valuable in studies with smaller sample sizes (fewer than 400 participants), where simple randomization might lead to imbalances that skew results. In B2B experiments, stratified randomization can prevent "whales" (high-value customers) from clustering in one group, which could distort revenue comparisons. The key is to carefully select variables that are closely tied to your primary success metric, as this justifies the added complexity.
Limitations
The biggest challenge with stratified randomization is avoiding unnecessary complexity. Limiting stratification to two or three variables is crucial; too many variables can fragment the sample into subgroups that are too small for meaningful analysis. For smaller samples, this can make the subgroups statistically insignificant. Additionally, managing assignments across multiple strata often requires specialized software to avoid errors, adding an administrative burden. It’s also important to adjust for the stratified variables during analysis; failing to do so negates the benefits of this method. Weighing the trade-off between precision and complexity is essential when deciding if this approach is the right fit for your multivariate testing (MVT).
4. Permuted Block Randomization
Permuted block randomization takes the concept of block randomization a step further by ensuring consistent balance within each block through randomized ordering. Here’s how it works: the sample is divided into blocks, and a predetermined number of participants in each block are assigned to different treatment variants. Unlike simple randomization – which can lead to imbalances until the study ends – this method guarantees balance at the conclusion of every block. For instance, in a block of four participants with a 1:1 ratio between two treatment variants, two participants will be assigned to each variant, but the order of assignments will be randomized. This method refines the block randomization approach to maintain balance throughout the study.
The process involves pre-assigning slots to treatments and then shuffling their order. In a block of four with two treatments, there are six possible assignment sequences (e.g., (T, T, C, C), (T, C, T, C), etc.). Importantly, block sizes should align with the number of treatment groups. For a 1:1 ratio, blocks of 2, 4, or 6 are appropriate, while for three groups or a 2:1 ratio, block sizes should be multiples of 3.
Balance Type
This method primarily ensures balance in sample size across treatment groups at regular intervals during the study. Unlike simple randomization, where group sizes might remain uneven until the study concludes, permuted block randomization restores balance after each block is completed. Additionally, when paired with stratification, it can balance key variables like gender by using separate randomization lists for different strata.
Best Use Case
Permuted block randomization is particularly useful in studies with small sample sizes, where simple randomization could lead to noticeable imbalances. It’s also ideal for studies where participants are enrolled sequentially, as it helps to prevent chronological bias. Furthermore, this method works well for experiments with planned interim analyses, as it ensures balanced groups at multiple checkpoints during the study.
Limitations
Despite its advantages, permuted block randomization has its drawbacks. One major issue is predictability. As Sealed Envelope highlights:
"The treatment allocation is predictable towards the end of a block. For this reason block sizes should be kept confidential and not shared with those randomising".
For example, in a block of two, the second assignment becomes obvious once the first is known. To address this, it’s recommended to vary block sizes randomly – such as alternating between blocks of 4, 6, and 8 – or, in unstratified designs, to use larger blocks (generally over 15). Another challenge is participant dropout. If participants leave before a block is completed, the balance is disrupted, which can create significant issues in smaller studies.
5. Minimization
Minimization is a method that actively balances treatment groups by calculating an imbalance score for key prognostic factors. Unlike simple randomization, which depends entirely on chance, minimization assesses how each possible treatment assignment will impact the distribution of critical variables – such as age, gender, or disease severity – every time a new participant is added to the study.
A biased coin approach can be incorporated to assign the preferred treatment with an 80% probability, while alternatives are assigned 20% of the time. This approach adheres to guidelines like the ICH E9, which emphasize:
"Deterministic dynamic allocation procedures should be avoided, and an appropriate element of randomisation should be incorporated for each treatment allocation".
This method ensures a more balanced allocation while meeting regulatory standards.
Balance Type
Minimization achieves balance across key covariates and prognostic factors without relying on complex stratification. By tracking the marginal totals of each stratifying variable independently, it can handle multiple factors simultaneously. For example, a trial with four stratifiers, each with three levels, would create 81 potential strata. While stratified randomization might struggle with empty cells in such a scenario, minimization handles it effectively.
Best Use Case
Minimization is particularly well-suited for small sample studies where simple randomization might lead to noticeable imbalances. It’s especially useful for balancing multiple important variables in studies with sequential enrollment. Because the calculations are performed in real time, balance is maintained throughout the study, rather than being assessed only at the end.
Limitations
The main challenge with minimization lies in its complexity. As noted:
"This type of adaptive randomization imposes tight control of balance, but it is more labor-intensive to implement because the imbalance scores must be calculated with each new patient".
To handle these calculations, specialized software or web-based tools are often required. Without the random element – such as the biased coin approach – the method can become predictable. If someone knows the characteristics of previously enrolled participants, they could potentially predict the next assignment. Additionally, minimization requires detailed participant data upfront, making it difficult to use in dynamic online settings where instant assignment is needed.
Comparison Table
The table below outlines the differences between various randomization methods, helping you determine the most suitable approach for your multi-variant test.
| Randomization Method | Balance Goal | Pros | Cons | Best Use Case |
|---|---|---|---|---|
| Simple Randomization | Pure Randomness | Easy to implement; maintains complete randomness; ideal for new users without historical data. | Can lead to unequal group sizes in small samples; risk of imbalance in key attributes. | Large trials (n > 100) or tests on new users with no historical data. |
| Block Randomization | Equal Sample Size | Ensures balanced group sizes over time, reducing mid-test imbalances. | May not balance specific demographics; predictable if block sizes are known. | Small to moderate trials (n < 100) without multiple key covariates. |
| Stratified Randomization | Covariate Balance | Balances groups based on key characteristics (e.g., age, gender) for greater precision. | Complex with many covariates; requires prior user data for grouping. | Trials where demographic factors are critical. |
| Permuted Block Randomization | Historical Balance | Maintains balance at the end of each block; prevents chronological bias. | Predictable towards block end; disrupted by participant dropout; requires confidential block sizes. | Sequential enrollment studies with planned interim analyses or small sample sizes. |
| Minimization | Multi-Factor Balance | Highly effective at balancing multiple covariates in small samples. | Computationally complex; requires sequential assignment and specialized software. | Small to moderate trials with several prognostic factors needing real-time balancing. |
KP Suresh, a Scientist in Biostatistics at the National Institute of Animal Nutrition and Physiology, highlights:
"Simple randomization works well for the large clinical trials (n > 100) and for small to moderate clinical trials (n < 100) without covariates, use of block randomization helps to achieve the balance".
Choosing the right method depends on your specific constraints. For tests involving new users without historical data, simple randomization is the go-to choice as it supports online allocation. However, if you have access to prior user data and can pre-assign groups, stratified randomization offers better control over confounding factors. This breakdown helps you align the method to your test’s needs effectively.
Conclusion
Randomization methods strike a balance between ease of use and accuracy, catering to different testing needs. They provide customized approaches to suit various experimental setups.
Selecting the right randomization technique is essential for maintaining the validity of your experiments. Effective randomization removes selection bias, ensures intervention groups are comparable, and isolates the actual effects of your changes.
Studies reveal that trials with poor or unclear randomization can inflate treatment effects by as much as 40%. This level of inaccuracy can lead to wasted resources and misguided decisions.
Your choice of method should align with the sample size and the data you have. For larger tests, simple randomization works well. When dealing with smaller samples, block randomization ensures balanced group sizes. If demographic factors might influence outcomes, consider stratified randomization or minimization to account for those variables.
Data availability also plays a key role. For experiments involving new users without prior data, simple randomization is a practical choice due to its compatibility with online allocation. On the other hand, if historical data is accessible, stratified randomization or minimization can help create balanced groups right from the start.
FAQs
How do I pick the right randomization method for my sample size?
When deciding on a randomization method, consider the specifics of your experiment and how participants will be divided into groups. For smaller samples, simple randomization is often effective. If you’re working with grouped samples, cluster randomization is better suited, as it addresses intra-cluster correlation. In online experiments, pinpoint the randomization unit – whether it’s a user, session, or another metric. Make sure your chosen method matches your data structure, response variability, and sample size to ensure reliable outcomes.
How can I prevent users from predicting their variant assignment?
To keep users from guessing their variant assignment during multi-variant tests, it’s crucial to use solid randomization methods. Options include simple randomization, block randomization, stratified randomization, or covariate adaptive randomization. For the process to stay unpredictable, rely on truly random or pseudorandom algorithms. These approaches help safeguard the test’s integrity by minimizing the likelihood of users figuring out their assigned variant.
What should I do if dropouts or uneven traffic disrupt group balance?
When dropouts or uneven traffic throw off the balance in your multivariate testing, seed randomization can be a game-changer. This approach keeps participants consistently assigned to specific groups, even when traffic fluctuates or participants drop out. By maintaining the integrity of randomization, seed randomization ensures your test results stay accurate and dependable, no matter the disruptions.