

Privacy-preserving analytics is transforming how businesses handle sensitive data, especially in marketing. Synthetic data – artificially generated datasets mirroring real-world patterns – offers a way to extract insights without compromising privacy. With regulations like GDPR and CCPA tightening data use, this approach is becoming essential.
Key Takeaways:
- Synthetic Data: Mimics real data patterns but doesn’t rely on actual personal records, reducing risks like breaches and re-identification.
- Techniques: Includes GANs, Variational Autoencoders, and Differential Privacy (DP), which ensures robust privacy by adding noise to data.
- Applications: Used for customer segmentation, campaign analysis, and predictive modeling while cutting costs and ensuring compliance.
- Benefits: Reduces data acquisition costs by 70%, speeds up campaign cycles by 40%, and ensures compliance with privacy laws.
Synthetic data is reshaping marketing analytics, enabling teams to balance insights with privacy. Below, we explore its methods, benefits, and real-world applications.
Deep Dive into the Synthetic Data SDK
sbb-itb-2ec70df
Key Concepts in Privacy-Preserving Analytics
Privacy Techniques Comparison: k-Anonymity vs Differential Privacy
Let’s dive into the core ideas behind privacy-preserving analytics, focusing on two major approaches: Differential Privacy and k-Anonymity.
Differential Privacy Fundamentals
Differential Privacy (DP) ensures that the results of an analysis remain almost the same, whether or not a specific individual’s data is included in the dataset. This is achieved through a mathematical framework that introduces carefully calibrated noise, controlled by a parameter called epsilon (ε). A smaller ε offers stronger privacy guarantees but may reduce the accuracy of the data analysis. DP’s post-processing property ensures that once the data is made private, any further analysis remains secure.
"The core promise of DP is intuitive yet powerful: the outcome of a differentially private analysis or data release should be roughly the same whether or not any single individual’s data was included in the input dataset." – Natalia Ponomareva et al., Google Research
Real-world applications of DP are already widespread. For instance, the U.S. Census Bureau used DP during the 2020 Census to safeguard the privacy of over 330 million residents. Similarly, companies like Google and Apple rely on DP in tools like RAPPOR and iOS telemetry. Research highlights the risks of skipping DP; generative models without it have been shown to memorize and reproduce real data, exposing up to 70% of individuals in some cases.
Next, let’s explore k-anonymity and related approaches that complement DP in certain scenarios.
k-Anonymity and Related Concepts
k-Anonymity works by making individual records indistinguishable from at least k‒1 others based on shared attributes like age, gender, or ZIP code. This is often done through generalization (e.g., replacing specific ages with age ranges) or suppression (removing certain data points).
However, k-anonymity has its flaws. One famous example comes from Latanya Sweeney, who re-identified Massachusetts Governor William Weld’s medical records by linking public voter registration data with quasi-identifiers like birth date, sex, and ZIP code. This shows how external datasets can compromise k-anonymized data.
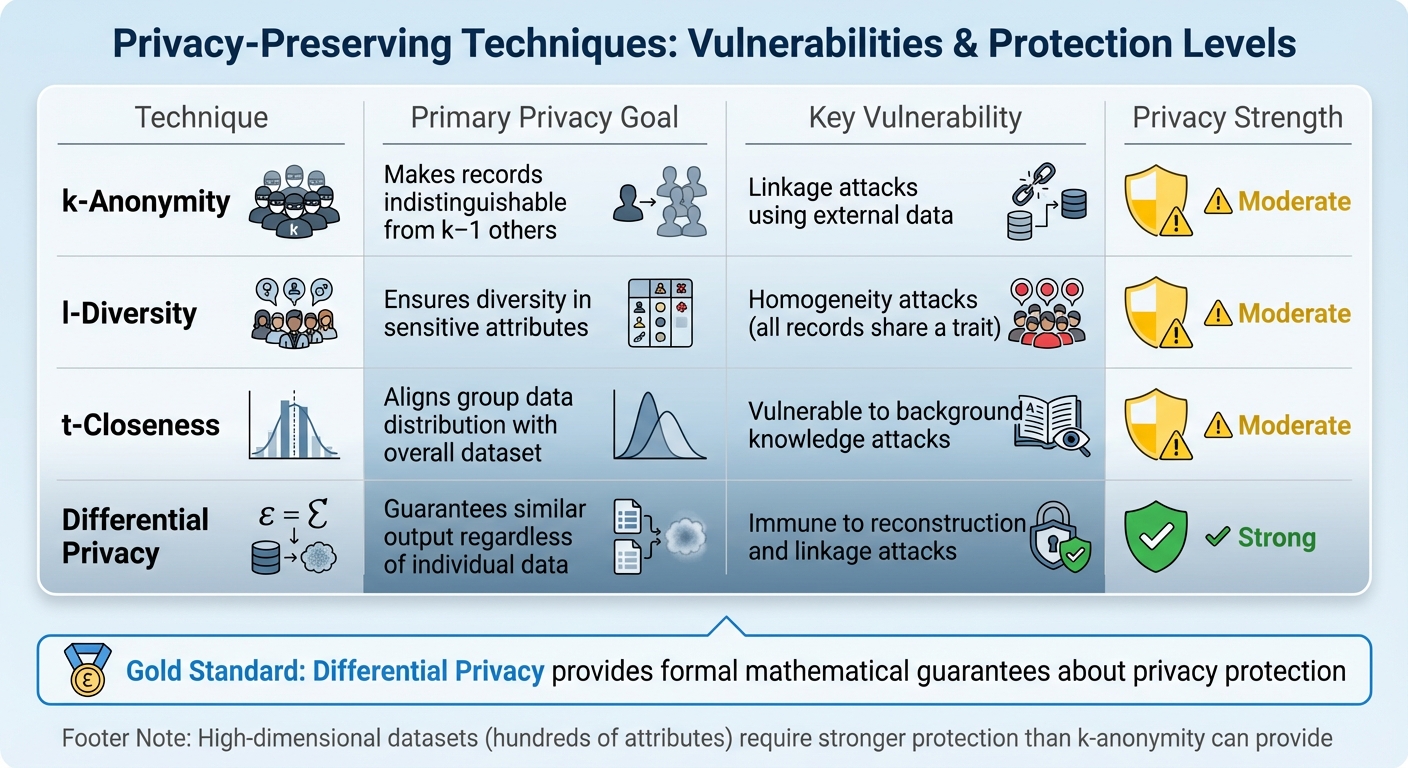
Here’s a quick comparison of privacy techniques and their vulnerabilities:
| Technique | Primary Privacy Goal | Key Vulnerability |
|---|---|---|
| k-Anonymity | Makes records indistinguishable from k‒1 others | Linkage attacks using external data |
| l-Diversity | Ensures diversity in sensitive attributes | Homogeneity attacks (all records share a trait) |
| t-Closeness | Aligns group data distribution with overall dataset | Vulnerable to background knowledge attacks |
| Differential Privacy | Guarantees similar output regardless of individual data | Immune to reconstruction and linkage attacks |
High-dimensional datasets, like marketing data with hundreds of attributes, pose a challenge for k-anonymity. The level of generalization needed to protect privacy often renders the data less useful. While extensions like l-diversity and t-closeness address some weaknesses, they still can’t match the robust guarantees of DP.
Given the sheer volume of data generated daily – over 2.5 quintillion bytes from 4.8 billion social media users – DP offers a stronger safeguard. While k-anonymity can still play a role in balancing privacy and utility, it fundamentally differs from DP. DP secures computations by adding noise, whereas k-anonymity alters the data itself.
"Differential privacy has emerged as the gold standard for privacy-preserving data analysis, providing formal mathematical guarantees about privacy protection." – Amiltha, Cybersecurity Professional
Techniques for Generating Synthetic Data
Synthetic data techniques make it possible to perform secure analytics while maintaining privacy. These methods range from cutting-edge neural networks to more traditional statistical models.
GAN-Based Approaches
Generative Adversarial Networks (GANs) create synthetic data by pitting two models – a generator and a discriminator – against each other. The result? Data that closely resembles the real thing.
For marketing analytics, tools like CTGAN and CTAB-GAN+ are tailored for tabular data, such as customer profiles and transaction records. Unlike GANs designed for images, these models use methods like mode-specific normalization to handle the complex, multimodal distributions often found in marketing datasets (e.g., purchase patterns that cluster around specific values).
Among these, CTAB-GAN+ is a standout. It’s recognized for generating high-quality data while preserving privacy. It’s particularly effective with imbalanced datasets, such as those where high-value customers are a small minority. By using conditional vectors and a "training-by-sampling" strategy, it ensures even these minority segments are well-represented.
Advanced GANs also address privacy concerns by incorporating Differential Privacy Stochastic Gradient Descent (DP-SGD), which adds noise during training to protect sensitive data while maintaining analytical usefulness.
"Differential Privacy (DP) provides theoretical guarantees on privacy loss but degrades data utility. Striking the best trade-off remains yet a challenging research question." – Zilong Zhao, TU Delft
However, GANs aren’t without their challenges. They can be tricky to train, often facing issues like mode collapse, where the generator produces limited variations, or oscillatory loss patterns that prevent stabilization. They also require significant computational resources – training can take over 2,000 epochs – and careful tuning of hyperparameters. High-cardinality features, like product SKUs with thousands of unique values, can also pose difficulties.
Non-GAN Approaches
Probabilistic Graphical Models (PGMs) offer a simpler, scalable alternative. Instead of modeling an entire dataset at once, they focus on the statistical relationships between smaller subsets of variables. This approach has proven effective for structured data and has even been recognized in NIST privacy competitions.
The Select-Measure-Generate paradigm is another method. It involves selecting key statistical queries, adding noise to ensure privacy, and then generating data that approximates these measurements. By framing the generation step as a projection problem, researchers have reduced errors in large marginals by up to 30% compared to using raw noisy data.
Statistical methods, like those using convex optimization techniques (e.g., multiplicative weights), are highly accurate for low-dimensional data. However, they struggle with scalability, making them less practical for datasets with hundreds of attributes, which are common in marketing analytics.
Emerging models, such as diffusion models and Large Language Models (LLMs), are now being explored for tabular data synthesis. These approaches leverage the capabilities of foundation models to capture complex relationships, signaling a shift beyond traditional GANs.
| Method | Best Application | Scalability Factor | Key Advantage |
|---|---|---|---|
| PGM | Statistical marginal preservation | Size of junction tree | Effective for structured data |
| GANs | High-dimensional data | Size of largest marginal | Captures intricate patterns |
| Direct Statistical | Low-dimensional data | Size of entire domain | Precise for specific applications |
| Diffusion/LLM | Complex tabular relationships | Size of largest marginal | Exploits advanced model capabilities |
For marketing teams, PGMs are often the most accessible starting point. They require less computational power than GANs and offer reliable results for tasks like customer segmentation and campaign analysis.
Evaluating Synthetic Data Quality
The quality of synthetic data is measured by fidelity, utility, and privacy.
- Fidelity metrics check how well the synthetic data mirrors the original dataset. For instance, bivariate accuracy ensures correlations (like age and spending) are preserved, while Centroid Similarity uses embeddings to compare high-dimensional distributions.
- Machine learning utility assesses performance by comparing models trained on synthetic data to those trained on real data. The TSTR (Train Synthetic, Test Real) method, for example, tests predictive models on real data after training them on synthetic data. Metrics like F1-score, AUROC, and Precision/Recall are commonly used. In one study, synthetic data outperformed real data in 73% of comparisons.
- Privacy metrics ensure synthetic data doesn’t replicate real records. Distance to Closest Record (DCR) measures how "close" synthetic data is to real data, aiming for a balance where data isn’t too similar (risking privacy) or too different (losing utility). Other tests, like Identical Match Share (IMS) and PII Replay, check for exact matches or leaked identifiers.
Adversarial robustness testing evaluates privacy risk by simulating attacks. Membership Inference Attacks (MIAs) determine if a specific record was part of the training data, while Attribute Inference Attacks (AIAs) test if sensitive fields can be inferred from other attributes. Research shows that just three attributes – gender, birth date, and postal code – can re-identify a large portion of the U.S. population.
Tools like SynthEval and mostlyai-qa provide benchmarks to validate synthetic data. Visual diagnostics, such as PCA projections, help confirm that synthetic and real data distributions overlap appropriately in lower-dimensional space.
Using a "holdout" strategy can further ensure quality. By comparing synthetic data to a reserved real dataset, teams can verify that synthetic samples are appropriately diverse without being overly similar to the training data. Monitoring model collapse through DCR comparisons can also reveal if the generator is producing a limited range of outputs.
These evaluation techniques help ensure synthetic data meets privacy requirements while remaining useful for analytics.
Applications in Marketing Analytics
Using privacy-focused techniques, marketing teams can now innovate without jeopardizing customer trust. Synthetic data is reshaping how marketers analyze customer behavior, test campaigns, and build predictive models. The market for synthetic data is expected to hit $1.79 billion by 2030, growing at an annual rate of 35.3%, while also cutting data acquisition costs by 70% and speeding up campaign cycles by 40%. Let’s dive into how this translates into key marketing applications.
Customer Segmentation and Targeting
Synthetic data has become essential for creating precise customer segments while maintaining privacy. By replacing real customer details, like names or purchase histories, with artificial records, marketers can analyze patterns that closely mimic actual consumer behavior. This is especially important given that personal customer data is tied to 44% of all breaches, and a single email address can be worth up to $90 for brands.
This technique also enables hyper-personalization. Synthetic personas, which reflect real-world demographics and psychographics, allow teams to simulate customer journeys and test strategies without risking real customers’ experiences. This kind of risk-free experimentation helps optimize spending and reduces uncertainty in the market.
Another major advantage is addressing gaps in data. For example, when niche customer groups are underrepresented in real datasets, synthetic data can create balanced examples, leading to more accurate targeting models. Additionally, its scalability allows marketers to generate millions of synthetic records, helping train machine learning models even when first-party data is limited.
A standout example comes from JPMorgan Chase, which used Persado’s generative AI platform to develop synthetic ad copy. By training on historical data without accessing personal information, they increased click-through rates by 450% and cut compliance review times by 70%.
"Synthetic data resolves the fundamental tension between delivering personalized experiences and respecting consumer privacy boundaries. It’s not just about compliance. It’s about unlocking campaign performance that was previously impossible to achieve."
– Marketing Technology Research
Campaign Performance Analysis
As third-party cookies phase out, synthetic data offers a privacy-friendly way to analyze campaign performance. By studying customer journey patterns without storing personal details, this method captures complex behaviors often missed by traditional approaches. For instance, it models "adstock" effects – how ad impact carries over time – and identifies when additional ad spend stops being effective. Marketing mix models built on synthetic data show 15–20% better predictive accuracy compared to standard regression models.
Nike used synthetic data during its "Never Done Evolving" campaign to simulate scenarios, such as comparing Serena Williams’ performances from 1999 and 2017. This testing phase uncovered emotional triggers that led to 23% higher engagement after the campaign launched.
Speed is another game-changer. Cloud-based synthetic data platforms can shrink campaign feedback loops from weeks to just hours, allowing marketers to adjust ad spend in near real-time. Synthetic panels also achieve creative performance scores that are within 5 percentage points of real-world results while slashing costs by 80%.
Security is a priority too. Techniques like differential privacy, which adds controlled noise to data, and GANs (generative adversarial networks), which create entirely new datasets, ensure that synthetic models maintain privacy. These methods have helped reduce potential ad fraud losses by 92% in 2023, saving $10.8 billion by detecting invalid traffic more effectively.
Beyond refining current campaigns, synthetic data strengthens predictive analytics for future strategies.
Predictive Modeling in Marketing
Predictive models powered by synthetic data are not only accurate but also fully compliant with GDPR and CCPA, eliminating risks tied to data breaches. These models excel in capturing rare events, like specific churn patterns or fraud cases, that are often underrepresented in real datasets. By generating large synthetic datasets, marketers can train models on these edge cases effectively. In fact, classifiers trained on synthetic data sometimes outperform those trained on original sensitive data because they pull from broader public data knowledge.
Netflix provides a great example. The company used synthetic engagement datasets to predict thumbnail preferences for its 200 million subscribers. Training neural networks on artificial viewing histories that mirrored real patterns boosted content discovery by 18% while avoiding extensive privacy reviews.
Costs for implementing synthetic data solutions are also manageable. For instance, a mid-sized company might spend $500 to $2,000 monthly on a privacy-first attribution stack. Regulatory bodies are on board too: in 2024, the UK’s Information Commissioner’s Office recognized synthetic data as a valid anonymization method, and EU GDPR agencies have suggested it may not even qualify as personal data.
Synthetic data offers marketers a way to transform analytics while respecting privacy. From segmentation and campaign analysis to predictive modeling, it allows for smarter, risk-free decision-making. At Growth-onomics, we are committed to leveraging these advanced methods to drive growth while safeguarding consumer trust.
Best Practices for Marketing Teams
Choosing the Right Synthetic Data Generation Tools
Start by determining the level of protection needed for your data. If you’re dealing with individual rows, record-level protection is sufficient. However, for multi-touch campaigns or datasets involving user interactions, user-level protection is a better fit.
The type of data you’re working with also influences tool selection. For structured data like demographics or purchase histories, statistical models such as PGM or MBI work well. For unstructured data, like text or images, deep learning methods – such as differentially private large language models (LLMs) or diffusion models – are more suitable.
It’s crucial to prioritize tools that offer formal Differential Privacy (DP) guarantees over heuristic methods. As Google Research puts it:
"Differential Privacy (DP) is a well-established framework for reasoning about and limiting information leakage, and is a gold standard for protecting user privacy".
When evaluating tools, focus on task-specific metrics like how well they perform in predictive tasks (e.g., churn prediction). Additionally, verify their privacy claims by conducting membership inference attacks to ensure they hold up under scrutiny.
Making these informed choices ensures you strike a balance between maintaining user privacy and preserving data utility.
Balancing Privacy and Utility
After selecting the right tool, the next challenge is balancing privacy with the usefulness of your data. Stronger privacy protections often result in less precise analytics, while weaker protections could expose sensitive customer details.
This balance is often determined by the epsilon (ε) value used in Differential Privacy. A smaller ε (below 1.0) offers stronger privacy but may obscure niche patterns in the data. Conversely, a higher ε improves accuracy but sacrifices some privacy. Studies indicate that synthetic data performance decreases significantly when ε drops to 4 or below.
To get the most out of your data while protecting privacy, allocate your privacy budget to low-dimensional marginals – combinations like age and purchase category – that capture key patterns with minimal noise. In some cases, using DP-projection methods to generate synthetic data can reduce error rates by as much as 30% compared to raw noisy measurements.
Another safeguard is applying post-processing filters to remove synthetic records that closely resemble real data. This step is critical because even a few data points – such as gender, birth date, and postal code – can uniquely identify a large percentage of Americans (63% to 87%).
Integrating Synthetic Data with Existing Marketing Workflows
Once you’ve chosen your tools and balanced privacy with utility, the next step is integrating synthetic data into your existing marketing processes. A useful approach is the "Select-Measure-Generate" framework: identify the key insights you need, measure them with privacy-preserving noise, and generate synthetic data that reflects these metrics.
Start with a pilot project to test how well the synthetic data integrates into your workflows. During this phase, exclude unique identifiers from the generative model to avoid issues like overfitting or potential privacy breaches.
Synthetic data should be seen as a complement to real data, especially given that privacy regulations can limit access to 60%-70% of user data. To ensure quality, validate the synthetic data using metrics like distribution, correlation, and task performance. Regularly run incrementality tests, such as geo-holdouts, to measure its effectiveness. As Synergist Digital Media points out:
"Synthetic data and privacy-first attribution modeling aren’t just buzzwords… They’re becoming the only way to do attribution without risking six-figure fines or completely alienating your audience".
At Growth-onomics, we help marketing teams integrate privacy-preserving analytics into their strategies, treating synthetic data as a valuable addition rather than a substitute for real data.
Conclusion
Synthetic data is reshaping how marketing teams handle analytics in a world that prioritizes privacy. With this technology, you no longer have to choose between gaining customer insights and staying compliant. It enables marketers to analyze trends, create predictive models, and refine campaigns without dealing with real personal data.
The benefits are striking: companies using synthetic data report 70% lower data acquisition costs and 40% faster campaign cycles. The global market for synthetic data is expected to jump from $218.4 million in 2023 to $1.79 billion by 2030, reflecting an annual growth rate of 35.3%. This isn’t just about dodging penalties – it’s about achieving new levels of performance that were out of reach with traditional methods.
This shift also changes how marketing success is measured. Experts point out how synthetic data transforms attribution modeling:
"Synthetic data resolves the fundamental tension between delivering personalized experiences and respecting consumer privacy boundaries. It’s not just about compliance. It’s about unlocking campaign performance that was previously impossible to achieve." – Marketing Technology Research, 2025
Moving from traditional tracking to probabilistic modeling offers a more transparent way to measure results. Instead of reporting exact figures, marketers work with confidence intervals (e.g., "this channel contributes ~23% with 95% confidence"), which often provide greater accuracy in the post-cookie landscape. Start small by testing this approach, validate it with holdout data, and educate stakeholders on the updated metrics.
At Growth-onomics, we specialize in helping marketing teams integrate synthetic data into their workflows, ensuring both privacy and performance. Privacy-first analytics isn’t just a trend – it’s the future. Synthetic data opens the door to secure, high-performing marketing strategies.
FAQs
How do I pick the right epsilon (ε) for differential privacy?
Selecting the right epsilon (ε) is all about finding the sweet spot between privacy protection and data usefulness. Smaller ε values strengthen privacy but can compromise the accuracy of the data. To strike this balance, you can use approaches like economic models, probabilistic risk analysis, or factor in the specific needs of your application. The key is to adjust ε based on your unique use case, ensuring you maintain both privacy and practical functionality.
How can I prove my synthetic data can’t re-identify real customers?
To show that synthetic data cannot re-identify real customers, you need to demonstrate low re-identification risk. This can be done using privacy metrics, such as distance-based scores, which evaluate how similar synthetic individuals are to real ones. The goal is to ensure that synthetic data points are indistinguishable from their real counterparts.
You can also run attack simulations to test the data’s resistance to re-identification attempts. Incorporating methods like differential privacy – which introduces carefully calibrated noise – further reduces the risk of exposing sensitive information. By combining these approaches, synthetic data can remain secure while still being useful for analysis.
When should marketing teams use PGMs vs GANs for synthetic data?
Marketing teams can benefit from Probabilistic Graphical Models (PGMs) when dealing with structured data. These models shine in scenarios where understanding relationships between variables is key, such as market research or tracking brand health. On the other hand, Generative Adversarial Networks (GANs) are ideal for generating realistic, high-dimensional data, like lifelike images or simulating intricate user behaviors. The choice between the two depends on factors like the type of data, privacy requirements, and whether you prioritize control or realism.