

Striking the right balance between overfitting and underfitting is the key to accurate demand forecasting. Overfitting happens when a model is too complex, memorizing noise instead of finding patterns, leading to poor performance on new data. Underfitting, on the other hand, occurs when a model is too simple, failing to recognize important trends, resulting in consistently poor predictions.
To fix these issues:
- Overfitting solutions: Use regularization, simplify the model, or stop training early.
- Underfitting solutions: Add features, reduce regularization, or train the model longer.
Both extremes hurt accuracy and decision-making. The goal is to find the "sweet spot" where the model generalizes well to new data without overreacting to noise. This balance directly impacts profits, inventory management, and customer satisfaction.
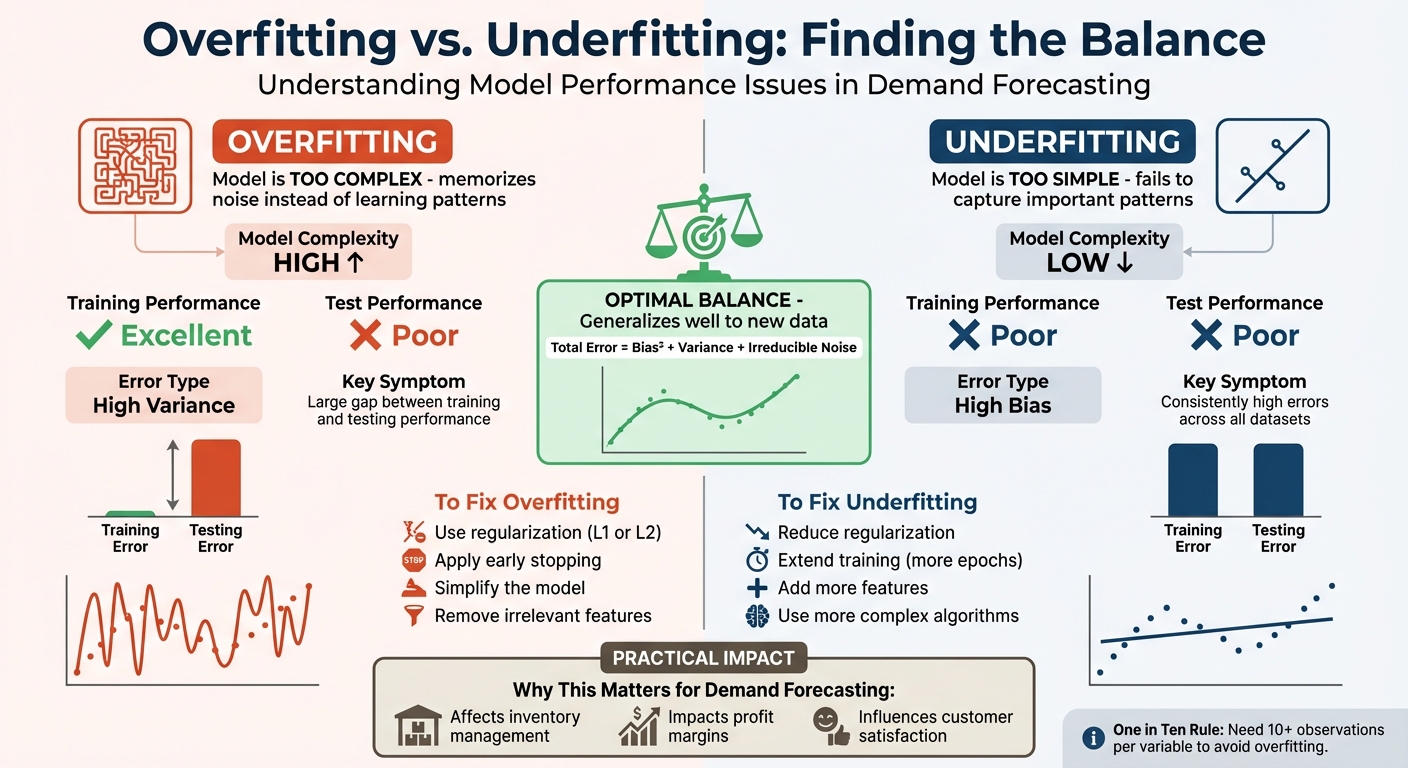
Overfitting vs Underfitting in Demand Forecasting: Key Differences and Solutions
How Can You Balance Overfitting And Underfitting In Time Series? – The Friendly Statistician
Overfitting vs. Underfitting: Key Differences
Overfitting and underfitting both lead to poor predictions, but they arise from very different problems in modeling. Overfitting happens when a model is too complex and ends up memorizing the training data instead of learning from it. On the other hand, underfitting occurs when a model is too simple and fails to capture important patterns in the data. These issues become clear when comparing how a model performs on training versus testing data.
One key sign of these problems is the gap between training and testing performance. Overfitting results in a model that performs extremely well on training data but struggles with new, unseen data. IBM explains it this way:
Overfitting: Training error is low, but testing error is significantly higher. Underfitting: Errors are consistently high across training and testing data sets.
This difference ties directly to the bias-variance tradeoff. Overfitting is linked to high variance, meaning the model is overly sensitive to small fluctuations in the data. In contrast, underfitting stems from high bias, where the model makes overly simplistic assumptions and misses key dynamics. Think of variance as the model being too reactive, while bias represents a lack of flexibility.
In demand forecasting, these issues have real-world consequences. An overfit model might perfectly replicate every small spike in historical data, but it won’t generalize well to future trends. An underfit model, however, might oversimplify seasonal demand, reducing it to a straight-line trend and ignoring important cycles.
Here’s a quick comparison of how these two issues differ:
Comparison Table
| Criteria | Overfitting | Underfitting |
|---|---|---|
| Model Complexity | High complexity; overly tailored to data | Low complexity; overly simplistic |
| Training Performance | Excellent performance on training data | Poor performance on training data |
| Test Performance | Struggles to generalize | Struggles to generalize |
| Error Type | High variance | High bias |
| Causes | Too many features; lack of regularization | Too few features; overly simple model |
| Observable Symptoms | Overly specific predictions; fits noise | Missed patterns; underestimates trends |
Causes and How to Fix Them
What Causes Overfitting
Overfitting happens when a model becomes too complex for the dataset it’s trained on. Instead of identifying meaningful patterns, the model starts memorizing random noise in the data. This issue becomes worse if the data itself is noisy – random fluctuations might be mistaken for actual trends. A small dataset also makes overfitting more likely. There’s a general guideline known as the "one in ten rule", which suggests having at least 10 observations for every independent variable to reduce the risk of overfitting.
On the other hand, underfitting is the result of a model being overly simplistic.
What Causes Underfitting
Underfitting occurs when the model lacks the complexity needed to capture the underlying patterns in the data. Eric Wilson, Director of Thought Leadership at the Institute of Business Forecasting, explains it well:
If the model is too simple and does not capture the complexity of data, it is underfitting.
Poor feature selection can make underfitting worse. For example, leaving out important variables like seasonal trends in a retail demand model can lead to overly basic predictions. Additionally, stopping the training process too early or applying too much regularization can limit the model’s ability to adapt to the data.
Fixing these problems requires careful adjustments to the model’s design and training process.
How to Fix These Problems
To address overfitting, you can:
- Increase regularization: Use L1 regularization to eliminate unnecessary coefficients or L2 regularization to shrink them.
- Apply early stopping: Halt training when performance on validation data starts to decline.
- Simplify the model: Reduce the number of layers or remove irrelevant features.
To fix underfitting, try:
- Reducing regularization: Allow the model more flexibility by lowering penalties.
- Extending training: Increase the number of epochs so the model has more time to learn patterns.
- Enhancing the feature set: Add interaction terms, polynomial features, or other relevant variables.
- Switching algorithms: If the current model remains too basic, consider using a more advanced approach.
These strategies help strike the right balance, enabling your model to capture meaningful patterns without being misled by noise.
sbb-itb-2ec70df
Pros and Cons
Getting the balance right when tuning a model is a tricky but essential task. Both overfitting and underfitting come with their own set of challenges, and understanding these trade-offs is key to improving how a model performs in practical scenarios.
Overfitting happens when a model becomes overly focused on the details of the training data. While this often results in high accuracy during training, it can lead to poor generalization because the model is too sensitive to noise or random fluctuations. Overfitted models might also require more costly data collection efforts or lose their flexibility when applied to new situations.
Underfitting, on the other hand, creates models that are simpler and easier to understand. They’re also computationally efficient and portable, making them appealing for stakeholders. However, these models fail to capture important patterns or trends, which means they perform poorly on both the training and test datasets. As Hagerty and Srinivasan pointed out:
A parsimonious but less true model can have a higher predictive validity than a truer but less parsimonious model
This underscores the importance of finding the right balance.
Striking a balance between these two extremes places your model in what experts often call the "Goldilocks Zone". This is where the model is neither too complex nor too simple, minimizing total error (calculated as Bias² + Variance + Irreducible Noise) and providing dependable predictions. However, reaching this sweet spot is no easy feat – it requires diligent tuning, extensive hyperparameter adjustments, and a solid understanding of the domain.
Here’s a closer look at the pros and cons of each approach:
Comparison Table
| Focus Area | Pros | Cons |
|---|---|---|
| Addressing Overfitting (Variance Reduction) | High accuracy on training data; captures detailed historical patterns; reduces sensitivity to random noise | Poor generalization; high test error; less flexible; costly data requirements |
| Addressing Underfitting (Bias Reduction) | Simpler, more interpretable models; lower computational demands; highly portable; low variance | Misses key patterns or trends; weak performance on training and test data; high bias |
| Balancing Both (Goldilocks Zone) | Optimal generalization; reduced total error; dependable predictions | Requires precise tuning, intensive hyperparameter optimization, and domain expertise |
These considerations lay the groundwork for diving into strategies to fine-tune models effectively.
Conclusion
Striking the right balance between overfitting and underfitting is crucial for accurate demand forecasting. This balance ensures that a model identifies meaningful patterns in the data without getting bogged down by irrelevant noise. A well-balanced model transitions smoothly from training data to real-world scenarios, avoiding the pitfalls of inventory mismanagement, wasted resources, and financial setbacks.
To maintain this balance, practical techniques like fine-tuning regularization and using cross-validation are invaluable. Regularization methods, such as L1 or L2, paired with early stopping, help control complexity while still allowing the model to capture critical trends. Cross-validation ensures the model performs well on unseen data, and monitoring learning curves can reveal overfitting – signaled by a drop in training loss alongside a rise in validation loss.
In mathematical terms, total prediction error is the sum of Bias², Variance, and Irreducible Error. In practice, the goal is to minimize bias and variance by finding the "sweet spot" of complexity. Start with simple models and only increase complexity when it leads to genuine improvements in validation performance. Combine this with domain knowledge to focus on features that truly influence demand, cutting out unnecessary noise in the process.
FAQs
How do I know if my demand model is overfitting or underfitting?
To figure out whether your demand model is overfitting or underfitting, start by comparing its performance on the training data versus the validation or test data. Overfitting occurs when the model excels on the training data but struggles with new, unseen data. This indicates that the model is too narrowly tuned to the training set, making it less effective in generalizing to other datasets. In contrast, underfitting happens when the model underperforms on both the training and validation data, suggesting it’s too simplistic to capture the data’s patterns.
Another way to assess this is by analyzing the model’s bias and variance. Overfitted models tend to have high variance (they’re overly sensitive to small fluctuations in the training data) but low bias. Underfitted models, on the other hand, show high bias (they oversimplify the problem) and low variance. Keeping an eye on prediction errors and the differences between training and validation results can help you pinpoint these issues and make the necessary adjustments to improve your model’s performance.
How can I strike the right balance between overfitting and underfitting in my demand forecasting model?
To find the right balance, start by making sure your model’s inputs reflect a broad range of historical data. Avoid focusing too much on specific details from the training set, as this can lead to overfitting – when the model memorizes irrelevant noise instead of identifying useful patterns.
Next, evaluate your model’s predictions by comparing them to actual outcomes. This helps you spot underfitting, which happens when the model oversimplifies and overlooks important trends. You can address these issues by using techniques like regularization, fine-tuning hyperparameters, and validating your model with unseen data. These steps improve the model’s ability to generalize and reduce the risk of overfitting.
Lastly, keep an eye on your model’s performance over time. Be ready to adjust its complexity to ensure it captures meaningful patterns without becoming unnecessarily complicated. Achieving this balance results in more reliable and accurate forecasts, which can help drive smarter decisions for your business.
Why is it essential to balance overfitting and underfitting in demand forecasting models?
Balancing overfitting and underfitting is crucial for accurate demand forecasting. Overfitting happens when a model becomes overly tuned to the training data, capturing even minor noise or irrelevant details. While it might perform well on the training set, it struggles with new, unseen data, leading to unreliable predictions and potentially flawed business decisions.
In contrast, underfitting occurs when a model is too simplistic, ignoring key trends and patterns in the data. This results in forecasts that are imprecise and fail to provide actionable insights. Finding the right middle ground between these extremes enables businesses to build models that generalize effectively, boosting forecasting accuracy and guiding smarter decisions.