
Fault tolerance ensures that real-time data pipelines continue processing without interruptions, even during failures like server crashes, network issues, or software bugs. Here’s how it works:
- Key Techniques:
- Redundancy & Replication: Data is stored across multiple nodes, so processing can continue even if one fails.
- Checkpointing: Regularly saves the system’s state to durable storage, allowing recovery from the last saved point.
- Processing Guarantees:
- At-Most-Once: Fast but risks data loss.
- At-Least-Once: Prevents data loss but may allow duplicates.
- Exactly-Once: Most reliable but resource-intensive.
- Challenges:
- Increased latency from checkpointing and recovery.
- Higher infrastructure costs due to redundancy and overprovisioning.
- Complex recovery in cloud environments with correlated failures.
- Tools:
- Apache Flink: Built-in checkpointing and state management for exactly-once guarantees.
- Spark Structured Streaming: Uses checkpoint locations and task redundancy for reliability.
- Business Impact:
- Reduces downtime, ensuring data accuracy for analytics, transactions, and optimized customer experiences.
- Supports real-time insights, improving decision-making and operational reliability.
Fault tolerance is critical for maintaining seamless data flow, especially in applications like payment processing, inventory tracking, and real-time personalization.
Easy, Scalable, Fault-tolerant Stream Processing in Apache Spark | Databricks
sbb-itb-2ec70df
How Fault Tolerance Works: Core Principles
Processing Guarantees in Real-Time Data Pipelines: At-Most-Once vs At-Least-Once vs Exactly-Once
Redundancy and Replication
Fault tolerance in real-time pipelines starts with redundancy – keeping multiple copies of data across distributed nodes. This setup ensures that if one node fails due to hardware or network issues, the system can continue processing using the remaining nodes without losing data. Modern systems often rely on clusters with hundreds of machines to maintain high availability and low latency.
A critical practice here is storing the pipeline’s internal state – like window buffers and user-defined variables – in distributed, reliable storage systems such as HDFS or Amazon S3. This ensures that even if a machine fails entirely, the processing can resume from the last saved state. In environments like Kubernetes, for example, if a pipeline pod fails, it can be terminated and restarted in a new pod (possibly with different resource allocations), while still accessing the preserved state from replicated storage.
For full fault tolerance, the data source also needs to be persistent and rewindable. Systems like Apache Kafka, which provide rewindable sources, work seamlessly with these replication strategies, emphasizing the importance of persistence in processing guarantees.
Checkpointing and State Management
Checkpointing involves periodically saving the pipeline’s global state, including source offsets and operator states, to durable storage. These save points act as recovery markers, allowing the system to resume processing after a failure.
One widely used method is Asynchronous Barrier Snapshotting (ABS). This technique captures snapshots without pausing the stream, with some platforms defaulting to intervals between 10 and 60 seconds.
The choice of storage backend for state management depends on specific requirements. Heap-based backends store state in memory for speed but are limited by memory capacity. Disk-based backends like RocksDB, on the other hand, can handle much larger states but are about 10 times slower due to serialization overhead. A key consideration: if you’re using Kafka sinks, be mindful of Kafka’s default transaction timeout of one minute. If your snapshot interval exceeds this timeout, messages might fail to commit at the sink.
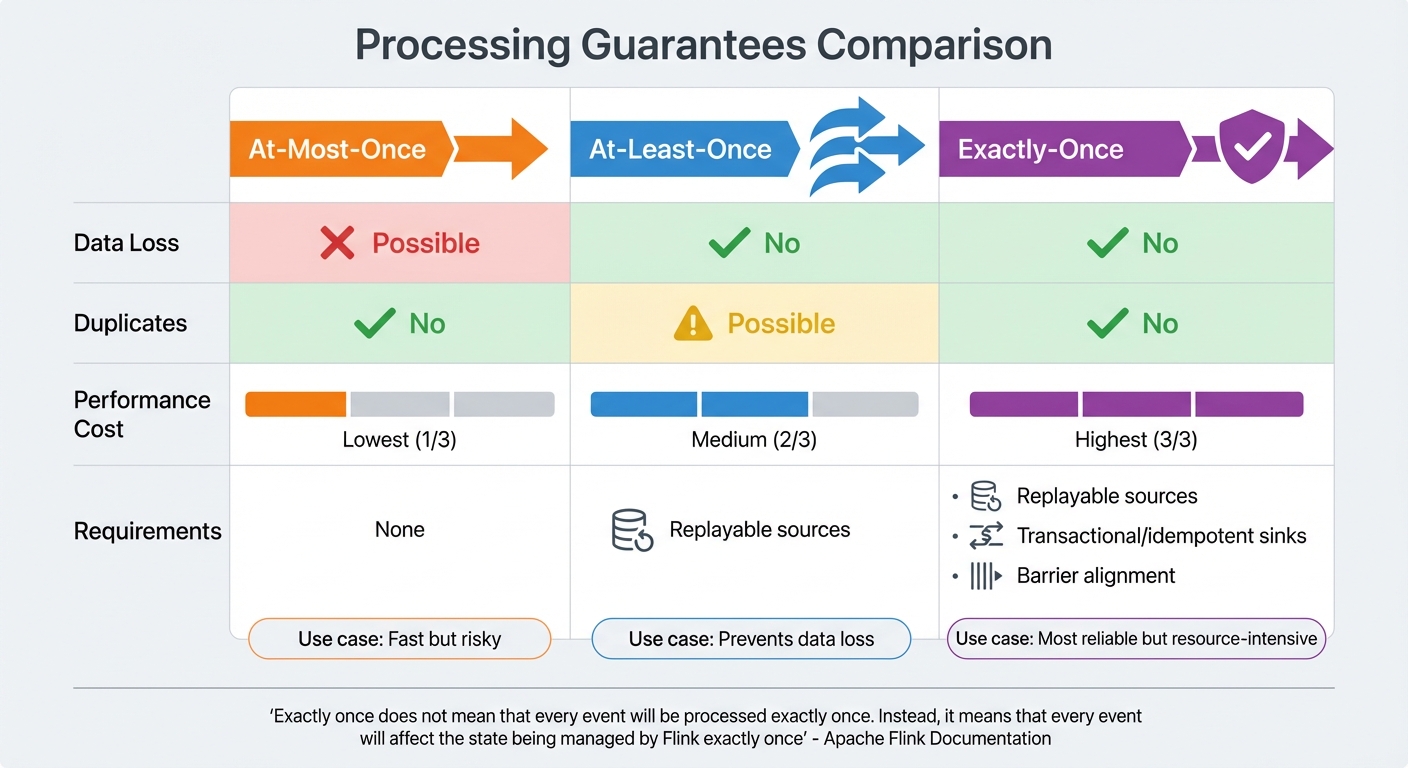
Processing Guarantees: At-Least-Once, At-Most-Once, Exactly-Once
While checkpointing secures the system’s state, processing guarantees determine how events are handled during failures. Different applications prioritize different levels of reliability:
- At-Most-Once: Events are processed only once, but data may be lost during failures since no retries occur.
- At-Least-Once: Ensures no data is lost by replaying events after a failure, though duplicates can occur unless the sinks are idempotent.
- Exactly-Once: The most reliable guarantee, ensuring that every event affects the system’s state exactly once. However, this comes with a higher performance cost and requires replayable sources, transactional or idempotent sinks, and barrier alignment across streams.
As the Apache Flink documentation explains:
"Exactly once… does not mean that every event will be processed exactly once. Instead, it means that every event will affect the state being managed by Flink exactly once".
| Guarantee | Data Loss | Duplicates | Performance Cost | Requirements |
|---|---|---|---|---|
| At-Most-Once | Possible | No | Lowest | None |
| At-Least-Once | No | Possible | Medium | Replayable sources |
| Exactly-Once | No | No | Highest | Replayable sources, transactional/idempotent sinks, barrier alignment |
To maintain consistency, avoid side effects in transformation steps. Non-transactional API calls can’t be rolled back if the system restarts from a snapshot. Keep external interactions limited to sources and sinks where they can be properly managed.
How to Implement Fault Tolerance: Practical Techniques
Using Apache Flink for Stream Processing

When it comes to implementing fault tolerance, Apache Flink offers a strong foundation with its built-in features like distributed checkpointing. To enable this, you simply call enableCheckpointing(n) on your StreamExecutionEnvironment, where n represents the interval in milliseconds. By default, Flink ensures EXACTLY_ONCE processing guarantees, but you can opt for AT_LEAST_ONCE if you need lower latency.
The choice of state backend significantly impacts performance. For smaller, in-memory states, the HashMapStateBackend is ideal due to its speed. On the other hand, for larger states that exceed memory limits, the EmbeddedRocksDBStateBackend is a better fit, though it comes with slower performance – about 10 times slower – because of disk operations and serialization overhead. RocksDB also supports incremental snapshotting, which stores only the changes made since the last checkpoint, making it more efficient.
In production environments, it’s essential to configure FileSystemCheckpointStorage to use a distributed file system like AWS S3 or HDFS. For instance, AWS S3 storage costs around $0.023 per GB per month. Avoid using JobManagerCheckpointStorage beyond testing scenarios, as it stores checkpoints in the JobManager’s heap and won’t survive a JobManager failure.
To optimize performance further, consider advanced settings. Enabling unaligned checkpoints can reduce checkpointing delays during backpressure, while setMinPauseBetweenCheckpoints helps maintain steady processing by spacing out snapshots. For long-term resilience, enable externalized checkpoints with RETAIN_ON_CANCELLATION, allowing you to manually resume jobs after cancellation.
Leveraging Spark Structured Streaming
Spark Structured Streaming provides another powerful option for fault-tolerant stream processing. It uses a checkpointLocation to store progress information and metadata, enabling stateful recovery after a failure. This ensures that the system can pick up right where it left off.
Spark also relies on redundancy by distributing tasks across multiple worker nodes. If one worker fails, the master node or load balancer redirects tasks to other healthy nodes. However, this redundancy increases costs, typically by 1.5 to 2 times. For high-end GPU instances, this can mean an additional $2–$4 per hour per duplicated node.
To achieve exactly-once processing, it’s critical to ensure that your data sources are replayable and that your sinks are either idempotent or transactional. Without these properties, Spark can only guarantee at-least-once delivery, which may lead to duplicate records.
Monitoring and Responding to Failures
Monitoring is a crucial part of maintaining fault tolerance. Keep an eye on system-level metrics like CPU usage, memory consumption, and I/O performance, along with pipeline-specific metrics such as task completion times, processing delays, and failed API requests. Set up automated alerts to notify your team when thresholds are breached – like five consecutive API failures or processing delays that exceed predefined limits.
"Fault tolerance inevitably makes it more difficult to know if components are performing to the expected level because failures do not automatically result in the system going down." – Fortinet
Incorporate retry logic with exponential backoff to handle temporary issues. For example, if an API timeout occurs, retry up to three times with increasing wait times between attempts. If the issue persists, log the error and alert an engineer. Implement circuit breakers to stop requests to failing systems, preventing failures from cascading across your infrastructure.
For streaming pipelines, monitor key metrics like backpressure levels, checkpointing success rates, and source offsets (e.g., Kafka partition offsets) to ensure the system can handle incoming data smoothly. Studies show that pipeline-parallel recovery can cut downtime by 50.5%, reducing "Time to First Token" (TTFT) to 3.8 seconds compared to 5.5 seconds with standard recovery methods.
Business Impact of Fault-Tolerant Pipelines
Reducing Downtime and Data Loss
When a real-time pipeline fails, the financial consequences can be immediate and severe. Fault-tolerant systems address this by using redundancy and spare capacity, ensuring operations continue seamlessly even if a primary component goes offline. This approach prevents systems from becoming overwhelmed during failures, maintaining performance within agreed SLAs.
Automated recovery mechanisms play a big role here. They can boost pipeline uptime from 95% to 99.5% and cut manual on-call interventions by over 70%. Features like checkpointing also speed up recovery, allowing systems to resume from the last saved state in minutes rather than hours. This not only reduces downtime but also frees up your team to focus on building rather than constantly troubleshooting.
Another critical feature is exactly-once processing, which eliminates data duplication and loss. This ensures accurate metrics for revenue tracking, transactions, and other key performance indicators. With this level of resilience, businesses can maintain uptime while delivering trustworthy analytics to support decision-making.
Improving Customer Journey Mapping and Analytics
Fault-tolerant pipelines are essential for maintaining data freshness, a key factor in accurate customer journey analytics and product recommendations. For instance, many recommendation engines aim to generate 90% of their suggestions based on user activity that’s no more than three minutes old. If a pipeline crashes and loses data, it creates gaps in customer journey maps, making it harder to track important behavioral events.
Idempotency is another important feature, ensuring that customer interactions are aggregated correctly. This is critical for real-time insights and financial reporting, where businesses often set strict standards – such as ensuring fewer than 0.5% of customer invoices contain errors in a given month. With robust monitoring and observability, the Mean Time to Detection (MTTD) for pipeline failures can be reduced by up to 80%, minimizing the chance of corrupted analytics.
By implementing fault-tolerant architectures with strong governance, businesses can see a 40% improvement in job success rates. This reliability fosters trust in data products, empowering teams to confidently use analytics for decisions around customer experience and marketing strategies.
Growth-onomics: Data-Driven Marketing Solutions
The operational reliability provided by fault-tolerant pipelines also supports data-driven marketing strategies. Growth-onomics, for example, leverages these systems to enhance marketing performance. Their focus on Customer Journey Mapping and Data Analytics depends heavily on real-time processing and data accuracy – key principles of fault-tolerant pipelines.
Such reliability ensures that data remains accurate, preventing analytics errors that could linger and disrupt decision-making. Growth-onomics applies these principles in areas like Performance Marketing and SEO, where dependable data pipelines are critical for tracking campaign performance, customer behavior, and conversion metrics in real time. With fresh, accurate data, businesses can implement real-time personalization and allocate marketing resources effectively, maximizing their impact.
Conclusion
Key Takeaways
Building fault-tolerant pipelines revolves around three key strategies: checkpointing to durable storage, selecting the right processing guarantees, and crafting recovery-friendly sinks. For instance, Hazelcast takes snapshots every 10 seconds, while Feldera opts for 60-second intervals. These intervals determine how much data needs to be replayed after a failure.
The decision between Exactly-Once and At-Least-Once processing depends on your use case. Choose Exactly-Once for critical tasks like payment systems or reward distributions, where duplicate processing could jeopardize financial accuracy or customer trust. On the other hand, At-Least-Once processing is often better suited for high-volume analytics, especially when paired with idempotent sinks using SQL MERGE or UPDATE statements. This approach balances performance and accuracy. To optimize recovery, align sink timeouts with snapshot intervals – for example, Kafka’s default transaction timeout is 1 minute.
"Don’t take dependencies on control planes in your data plane, especially during recovery." – AWS Whitepaper
Another crucial step is pre-provisioning spare capacity to handle node failures without waiting for new resources to be allocated. Regularly monitor checkpoint latency, as delays caused by slow external services or garbage collection pauses can significantly increase sink latency.
These technical practices not only ensure system stability but also safeguard data integrity, laying the foundation for reliable and actionable business insights.
Fault Tolerance and Business Growth
A resilient pipeline does more than just prevent system crashes – it ensures the accuracy of real-time data that fuels business growth. For example, customer journey mapping relies heavily on uninterrupted data flow. A single pipeline failure could lead to gaps in behavioral tracking, potentially resulting in less effective marketing decisions. Companies like Growth-onomics, which specialize in Data Analytics and Performance Marketing, depend on continuous and precise data streams to deliver real-time personalization and campaign tracking.
Automated recovery systems also reduce downtime and limit the need for manual intervention. This reliability ensures accurate analytics for customer engagement strategies, counting every click, purchase, and interaction exactly once. When your data infrastructure is built to endure failures without compromising accuracy, your marketing teams can confidently rely on a true single source of truth. This confidence translates into smarter, more effective decision-making that drives business success.
FAQs
How do I choose between at-least-once and exactly-once processing?
When deciding between these options, it all boils down to what your application needs most: precision or speed.
Exactly-once processing guarantees that every record is handled only once, making it perfect for scenarios like financial transactions where accuracy is non-negotiable. However, this level of precision can introduce some latency to the process.
On the other hand, at-least-once processing ensures no data is lost, even if it means some duplicates might occur. This approach works well in situations where speed, lower costs, or tolerance for duplicates take precedence.
Your choice should reflect whether your focus is on absolute correctness or maximizing performance.
What checkpoint interval should I use for my pipeline?
The best checkpoint interval for your system depends on its specific performance and reliability requirements. A good starting point is a 1-minute interval, as this strikes a balance between faster recovery times and lower system overhead. From there, you can fine-tune the interval based on your system’s resource availability and performance metrics. Regularly monitor your system to identify the sweet spot where fault tolerance is maintained without slowing down throughput.
How can I avoid duplicates when failures trigger replays?
To avoid duplicates when reprocessing data in real-time pipelines, implement idempotency. This approach ensures that even if the same data is processed multiple times, the outcome remains consistent. A practical way to achieve this is by assigning unique identifiers to each transaction or batch, enabling the system to identify and skip data that has already been handled.
Pairing idempotent logic with fault-tolerant techniques, such as checkpointing and retry strategies, further strengthens data integrity. These methods help the system recover smoothly while preventing errors or inconsistencies during replays.