

Want to track your marketing impact effectively? You have two main options: deterministic and probabilistic tracking. Deterministic tracking uses exact identifiers like emails or logins for high precision but works only with identified users. Probabilistic tracking, on the other hand, relies on statistical models to estimate user journeys, offering broader coverage for anonymous traffic.
Here’s the key difference: deterministic tracking provides near-perfect accuracy (95-99%) by matching data directly, while probabilistic tracking estimates matches with 60-90% accuracy, depending on data quality. As privacy regulations tighten and cookies disappear, combining both methods can help you balance precision and reach.
Quick Overview:
- Deterministic Tracking: Precise, relies on user-provided data (e.g., logins, emails), ideal for compliance-heavy industries.
- Probabilistic Tracking: Estimates matches using signals like IPs or device types, great for anonymous, cross-device journeys.
- Best Approach: Use deterministic for known users and probabilistic to fill gaps in fragmented data.
Takeaway: Blend both tracking methods to ensure accurate insights while adapting to privacy changes.
What Is Deterministic Tracking?
Deterministic tracking connects marketing touchpoints to conversions using unique identifiers. It’s a binary system: either the match is 100% certain, or it’s not.
These identifiers include login credentials, hashed email addresses, user IDs, phone numbers, and authenticated device identifiers like Apple’s IDFA or Google’s GAID. When users log in or provide their email, this information ties all their actions together across devices and sessions.
Since deterministic tracking relies on personally identifiable information (PII), it requires explicit user consent to comply with regulations like GDPR and CCPA. This consent ensures transparency and reduces compliance risks for businesses while protecting user privacy.
Deterministic tracking is highly accurate, delivering verified matches 95% to 99% of the time. However, match rates vary by industry. SaaS companies often achieve around 70%, while direct-to-consumer brands typically see rates between 25% and 35%.
How Deterministic Tracking Works
Deterministic tracking turns anonymous browsing into a unified customer view through three main steps:
- Identity Establishment: Collect a unique identifier, such as a login or email, and store it in your CRM or CDP.
- Touchpoint Instrumentation: Tag marketing channels with persistent parameters to track user interactions.
- Session Stitching: Link anonymous sessions to identified users retroactively.
This process depends on server-side tracking to remain effective as browser-based tracking becomes more restricted due to cookie deprecation and intelligent tracking prevention. These steps ensure precise tracking, enabling its unique advantages.
Benefits of Deterministic Tracking
The standout benefit of deterministic tracking is its precision. With 95% to 99% accuracy, it removes the uncertainty from tracking conversions.
This method also excels in auditability and transparency, making it ideal for industries like healthcare and finance that require strict compliance. Deterministic data provides a clear trail, allowing organizations to trace every conversion back to its source. As Danika Rockett, Sr. Manager of Technical Marketing Content at RudderStack, puts it:
"Deterministic models offer precision and auditability." – Danika Rockett, Sr. Manager, Technical Marketing Content, RudderStack
Another major advantage is its ability to optimize marketing spend. Deterministic data acts as a calibration tool for other attribution models. For instance, if your broader model attributes 40% of conversions to paid social but deterministic data shows only 28%, you’ve uncovered a bias. On a $50,000 monthly budget, this discrepancy could lead to $60,000 in misallocated spending annually.
Lastly, deterministic tracking is excellent for following cross-device activity. Once a user logs in, their journey across desktop, mobile, and tablet is seamlessly connected – something cookie-based tracking will struggle to achieve in 2026.
What Is Probabilistic Tracking?
Probabilistic tracking relies on statistical algorithms and aggregated data to estimate how likely it is that various touchpoints are part of the same user journey. Unlike deterministic tracking, which uses exact identifiers, probabilistic methods assign a confidence score – like 85% or 92% – to indicate the likelihood of a match.
This method becomes crucial when traditional identifiers, such as cookies, are unavailable. For instance, when users browse anonymously or block cookies, probabilistic tracking steps in by analyzing "soft signals." These signals include details like IP addresses, device types, operating systems, browser versions, screen resolution, geolocation, and behavioral patterns such as time of visit and click sequences. While it prioritizes broader coverage, it doesn’t aim for the same level of precision as deterministic tracking.
The accuracy of probabilistic tracking typically falls between 60% and 90%, depending on the quality of the data and the sophistication of the models used. Some advanced techniques have even achieved up to 97.3% accuracy in cross-device identification. Danika Rockett, Sr. Manager of Technical Marketing Content at RudderStack, explains:
"Probabilistic models use statistical inference to handle uncertainty and incomplete data, enabling broader identity resolution across fragmented touchpoints."
As third-party cookies become less common and privacy frameworks like Apple’s App Tracking Transparency limit traditional tracking, probabilistic methods are becoming increasingly vital. They help marketers maintain visibility into customer journeys, even when deterministic data isn’t available. Let’s take a closer look at how probabilistic tracking operates.
How Probabilistic Tracking Works
Probabilistic tracking relies on machine learning algorithms to process vast datasets, identifying patterns and connections between touchpoints. Instead of personal identifiers, it collects contextual signals and uses statistical models – such as Bayesian models, Markov chains, and logistic regression – to calculate the likelihood of a match.
For example, imagine a user researching a product on their iPhone at 9:00 PM from a Chicago IP address, then completing the purchase on their laptop at 9:15 PM. Even without a login, the algorithm can analyze the behavioral patterns and calculate the probability that it’s the same user.
The more data the system processes, the better it gets. With millions of data points, these algorithms can detect subtle patterns that smaller datasets might miss. They also continuously improve by learning from new information, refining their predictions over time.
However, there are trade-offs. A 10% margin of error in attribution could result in $5,000 in misallocated spending for a business with a $50,000 monthly marketing budget. To mitigate this, many teams set confidence thresholds – only triggering high-cost actions when the match probability exceeds a certain level, such as 90%.
Benefits of Probabilistic Tracking
One of the biggest advantages of probabilistic tracking is its ability to provide broad coverage. While deterministic tracking is limited to logged-in users, probabilistic methods can capture anonymous traffic and cross-device journeys throughout the entire funnel. This makes it especially valuable for top-of-funnel activities, where first-party data isn’t yet available.
It also aligns better with privacy regulations. By relying on aggregated or pseudonymized data instead of personally identifiable information, probabilistic tracking is more adaptable to frameworks like GDPR and CCPA – an increasingly important factor as privacy laws evolve.
Another strength is its ability to connect cross-device interactions without requiring logins. For instance, it can link a user who sees an ad on their phone, researches on a tablet, and completes a purchase on a desktop. And because it doesn’t rely on specific platforms, it scales effectively across the open web.
As Jack Browning from Northbeam puts it:
"Deterministic attribution models provide precision, while probabilistic attribution provides coverage."
Understanding these strengths helps marketers determine when to use probabilistic tracking alongside deterministic methods, ensuring they have the right tools to achieve their campaign goals. Together, these approaches offer a comprehensive view of modern customer journeys.
Deterministic vs Probabilistic Tracking: Key Differences
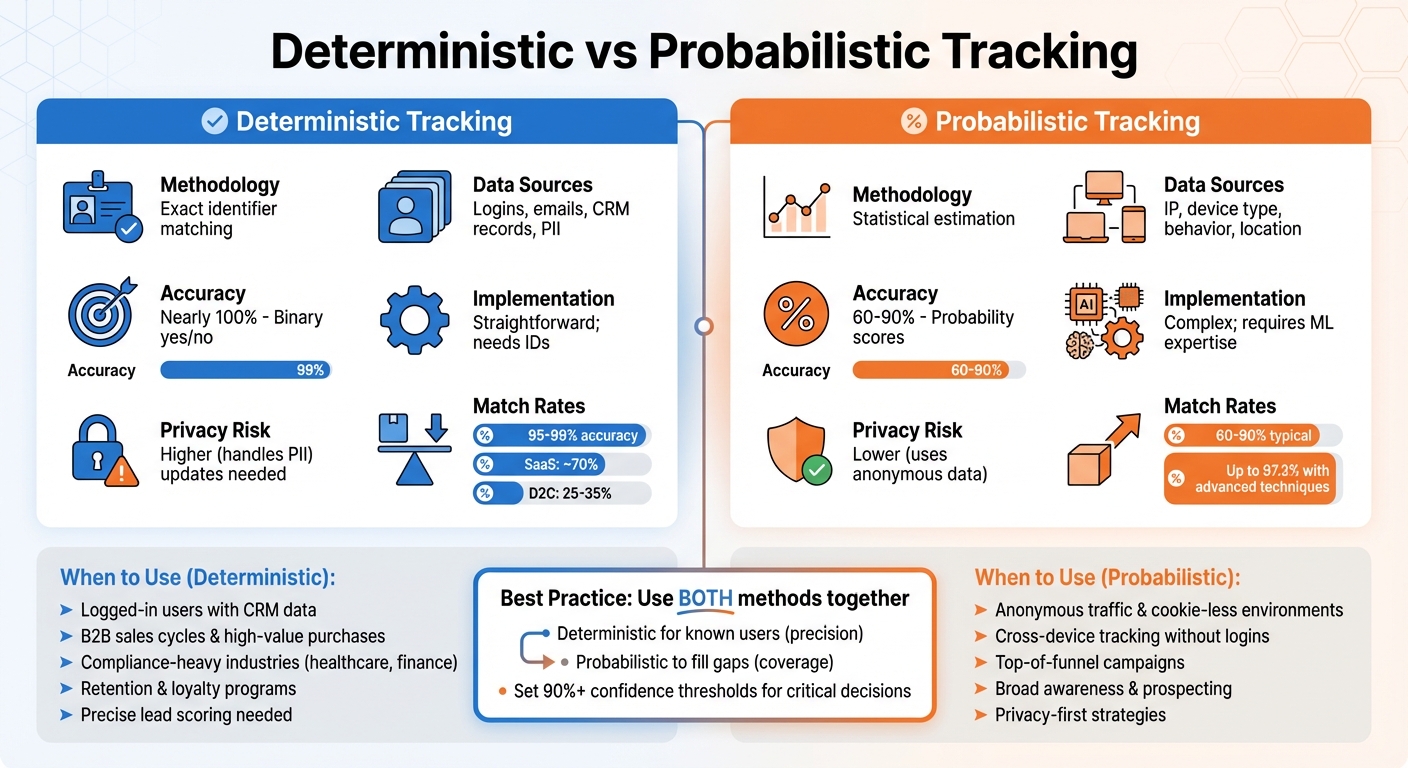
Deterministic vs Probabilistic Tracking: Key Differences and When to Use Each Method
Let’s break down the main differences between deterministic and probabilistic tracking methods to better understand their unique strengths and limitations.
How the Two Methods Differ
Deterministic tracking is all about certainty. It relies on exact identifiers – like email addresses or user IDs – to establish direct, verifiable connections between touchpoints. In contrast, probabilistic tracking uses statistical models to estimate the likelihood that different interactions come from the same user.
The key takeaway? Deterministic tracking gives you verified matches, while probabilistic tracking provides confidence scores. This impacts both accuracy and complexity. Deterministic tracking delivers near-perfect accuracy, as it’s based on verified data. Probabilistic methods, however, rely on statistical estimates, with accuracy ranging from 60% to 90%, depending on the quality of the data and the algorithms used.
Important Note: Deterministic tracking requires user-provided data and explicit consent, whereas probabilistic tracking uses anonymized signals.
| Feature | Deterministic Tracking | Probabilistic Tracking |
|---|---|---|
| Methodology | Exact identifier matching | Statistical estimation |
| Data Sources | Logins, emails, CRM records, PII | IP, device type, behavior, location |
| Accuracy | Nearly 100% (Binary yes/no) | 60–90% (Probability scores) |
| Implementation | Straightforward; needs IDs | Complex; requires ML expertise |
| Privacy Risk | Higher (handles PII) | Lower (uses anonymous data) |
| Scalability | Rigid; manual updates needed | Flexible; adapts to new data |
Pros and Cons of Each Method
Deterministic tracking stands out for its precision. It’s ideal for industries like finance and healthcare, where compliance and accuracy are crucial. It provides clear audit trails and supports one-to-one targeting, making it a reliable choice for high-stakes decisions in B2B marketing. However, it has its limitations. It only works for identified users, leaving gaps when identifiers like logins or emails aren’t available. Plus, managing user consent under regulations like GDPR and CCPA can be a challenge. Another downside? It may oversimplify complex customer journeys that span multiple devices.
On the other hand, probabilistic tracking shines when dealing with fragmented customer journeys. It’s particularly effective for scaling across anonymous traffic and is less affected by the loss of cookies or Apple’s App Tracking Transparency policies. Over time, as more data is processed, its accuracy often improves . But it’s not without trade-offs. Since it’s based on estimates, a 10% misattribution rate could lead to significant financial consequences – like $60,000 in misallocated spending annually for a company with a $50,000 monthly marketing budget. Additionally, the complexity of machine learning models can make auditing more difficult, and fingerprinting techniques face ongoing regulatory scrutiny .
"Deterministic models offer precision and auditability. Probabilistic models handle incomplete data and adapt over time." – Danika Rockett, Sr. Manager, Technical Marketing Content, RudderStack
Understanding these differences is essential for selecting the right tracking method for your campaigns. Each approach has its strengths, but the choice ultimately depends on your specific goals and constraints.
sbb-itb-2ec70df
How to Choose the Right Tracking Method
Deciding between deterministic and probabilistic tracking isn’t about picking one over the other – it’s about finding the right fit for your business. The choice boils down to several factors: the quality of your data, the nature of your industry, your business goals, and the technical resources you have at hand.
Start with your data. If you have access to complete, reliable identifiers like email addresses or user IDs, deterministic tracking is the better option. But when your data is scattered – like anonymous visitors hopping between devices – probabilistic tracking steps in to bridge those gaps.
Your industry plays a big role too. Heavily regulated fields like healthcare (under HIPAA) and finance need the clear audit trails and precise results that deterministic tracking offers. On the other hand, industries with a strong focus on privacy often lean on probabilistic methods, which work with anonymized data.
Think about your business objectives. If accuracy is critical – say, for CRM deduplication or managing long, high-value B2B sales cycles – deterministic tracking is the way to go. But if your focus is on broad awareness campaigns or finding new customers, probabilistic tracking shines by offering the scale you need.
Lastly, consider your technical setup. Deterministic tracking is relatively simple to manage with basic SQL skills. In contrast, probabilistic tracking requires advanced machine learning expertise and the tools to handle large-scale pattern recognition.
When to Use Deterministic Tracking
Deterministic tracking works best in situations where users are logged in and you have solid CRM data. If your business relies on account creation – like SaaS platforms, subscription services, or membership-based sites – you already have verified identifiers that make deterministic tracking a natural choice.
This method is particularly valuable for businesses with long B2B sales cycles. For example, in FinTech or enterprise software, where high-ticket purchases are common, you can’t afford to guess. Deterministic tracking ensures precise lead scoring and account-based attribution, directly linking your marketing efforts to revenue.
It’s also a great fit for retention and loyalty programs. Known customers are far more likely to convert – over 60% compared to less than 20% for new prospects – so deterministic tracking helps you personalize remarketing strategies and accurately measure subscription funnels.
Additionally, deterministic tracking is essential in industries where compliance and auditability are non-negotiable. Financial transactions, healthcare communications, and other regulated activities benefit from the clear, detailed attribution trails that deterministic tracking provides.
"Deterministic attribution provides clarity and confidence in environments where guessing isn’t good enough." – AttributionApp
When to Use Probabilistic Tracking
Probabilistic tracking is your go-to when traditional identifiers are unavailable or incomplete. With the decline of third-party cookies and restrictions like Apple’s App Tracking Transparency, probabilistic models rely on behavioral signals to maintain visibility into customer journeys.
It’s particularly effective for cross-device tracking. For instance, if a customer sees an ad on their phone during their morning commute but completes the purchase on a desktop later, probabilistic tracking can connect these interactions using patterns such as IP addresses, device types, and browsing behaviors.
This method also excels in top-of-funnel campaigns where reach matters more than pinpoint accuracy. Whether you’re running prospecting campaigns or building lookalike audiences, probabilistic tracking provides the coverage you need without requiring users to log in. While its accuracy typically ranges from 60% to 90%, that level of precision is often enough for discovery and awareness efforts.
Using Both Methods Together
The most effective strategies often combine deterministic and probabilistic tracking. Think of deterministic tracking as your foundation for precision, while probabilistic modeling fills in the gaps where identifiers are missing.
Start by implementing deterministic tracking for all known, logged-in users to create a high-confidence baseline for your reporting. Then, layer probabilistic models on top to piece together fragmented journeys – like when users switch between a mobile app and a desktop browser.
This hybrid approach allows you to leverage the 100% accuracy of deterministic tracking while extending your reach through probabilistic estimates. You can even set confidence thresholds (e.g., 90% or higher) for probabilistic matches to guide critical budget decisions.
Regular audits of your tracking system can help identify blind spots caused by cookie loss or ad blockers. These gaps may require additional probabilistic modeling. Some advanced teams go a step further by blending marketing mix modeling, multi-touch attribution, and incrementality testing to achieve even greater accuracy.
"Deterministic models provide precision, while probabilistic attribution provides coverage." – Jack Browning, Northbeam
Ultimately, strengthening your first-party data collection – through account creation and loyalty programs – maximizes your deterministic tracking capabilities. At the same time, probabilistic tracking remains a valuable tool for addressing gaps you can’t avoid. By integrating both methods, you create a robust tracking strategy that improves your campaign performance across the board.
Setting Up Tracking with Growth-onomics
Tracking effectively requires more than just installing a pixel. Growth-onomics takes a more robust approach by creating a first-party data strategy. This means relying on owned identifiers – like email addresses, user IDs, and CRM records – instead of third-party cookies. This shift ensures compliance with privacy regulations like GDPR, CCPA, and iOS updates, while also building a system that’s resilient to ongoing privacy changes.
The setup process unfolds in three key phases:
- Foundation Phase: Growth-onomics begins by establishing critical elements like first-party tracking infrastructure, consent management platforms, and UTM parameters to ensure accurate tracking.
- Expansion Phase: During this stage, CRM systems, ad platforms, and analytics tools are integrated. These systems work together to link multichannel touchpoints using deterministic rules.
- Optimization Phase: Attribution dashboards are introduced to analyze data and guide budget decisions based on reliable insights.
This phased approach creates a seamless view of the customer journey, connecting every interaction – from the first ad impression to the final purchase.
Mapping the Customer Journey
Growth-onomics excels at piecing together fragmented touchpoints to form a unified customer journey. Logged-in users are matched using deterministic methods, while anonymous visitors are tracked with probabilistic models. This ensures no touchpoint is overlooked, whether it’s an ad click or a purchase.
Advanced Analytics and Data Control
Growth-onomics doesn’t stop at the basics. They implement advanced statistical models – like Markov chains and machine learning algorithms (e.g., logistic regression and random forest) – to enhance their tracking methods. These models work alongside deterministic and probabilistic techniques to provide deeper insights. Additionally, they help businesses shift their tracking systems into dedicated data warehouses or lakehouses, ensuring greater control and compliance.
Driving Campaign Efficiency
To maximize campaign performance, Growth-onomics connects ad spend directly to conversion values. They calculate real-time ROAS (Return on Ad Spend) and customer acquisition costs, offering businesses actionable insights. Confidence thresholds for probabilistic matches – set at 90% or higher – guide spending decisions with precision. By separating deterministic conversions from probabilistic estimates in parallel reports, they validate the accuracy of their models and minimize the risk of budget misallocations.
This data-driven approach ensures that every dollar spent is backed by high-confidence insights, helping businesses make smarter, more informed decisions.
Conclusion
Deciding between deterministic and probabilistic tracking comes down to knowing which approach aligns with your business needs. Deterministic tracking relies on direct identifiers, offering near-perfect accuracy – making it ideal for precise tasks like retention marketing, CRM management, and industries with strict compliance requirements. On the other hand, probabilistic tracking uses statistical models to link anonymous sessions, making it a better fit for top-of-funnel campaigns and cross-device attribution.
For most businesses, a combination of both methods works best. Modern tracking strategies often use deterministic data as a reliable foundation, then layer probabilistic models to fill in the gaps where cookies fall short or users remain anonymous. This hybrid approach enhances accuracy while extending reach across fragmented customer journeys. As third-party cookies phase out and privacy regulations grow stricter, this balance has become the go-to solution. In fact, 93% of brands and agencies anticipate adopting contextual targeting – a probabilistic method – by late 2025.
To get started, evaluate your current tracking setup. Pinpoint where you’re losing visibility – whether it’s users blocking tracking on iOS, challenges with cross-device attribution, or anonymous browsing. Build a strong base with first-party deterministic data through logins and account creation, and then use probabilistic models to cover the blind spots. This approach ensures your tracking strategy stays effective in an ever-changing privacy landscape.
FAQs
How do privacy laws affect deterministic and probabilistic tracking?
Privacy laws like GDPR and CCPA are reshaping how companies approach tracking methods, particularly deterministic and probabilistic techniques.
Deterministic tracking depends on precise identifiers like cookies, device IDs, or personally identifiable information (PII). However, with stricter regulations in place, collecting and using this kind of data has become more difficult. These laws require explicit user consent, making it increasingly challenging for organizations to rely solely on deterministic methods for tracking.
On the flip side, probabilistic tracking takes a different route. It uses aggregated, anonymized data and statistical models to predict user behavior without depending on direct identifiers. This method aligns more easily with privacy regulations and remains a practical option as third-party cookies are gradually phased out. By prioritizing privacy while still delivering valuable insights, probabilistic tracking presents a scalable way forward in the evolving world of data-driven marketing.
Ultimately, privacy laws are steering businesses toward probabilistic tracking, pushing for solutions that meet compliance requirements while still providing actionable data.
What are the benefits of using both deterministic and probabilistic tracking together?
Combining deterministic and probabilistic tracking offers marketers a more thorough and nuanced view of customer behavior across multiple channels and devices. Here’s how they differ: deterministic tracking relies on exact identifiers, like email addresses or device IDs, to deliver highly precise and dependable data. On the other hand, probabilistic tracking uses statistical models to make educated guesses about user identities, which is especially useful when data is incomplete or privacy restrictions limit access.
When used together, these methods create a well-rounded strategy. Deterministic tracking ensures accuracy and provides compliance-friendly data, while probabilistic tracking helps fill in the gaps, maintaining continuity even in scenarios where cookies or other identifiers are unavailable. This hybrid approach empowers marketers with better insights, smarter decision-making, and a stronger return on investment for their campaigns.
How do businesses choose between deterministic and probabilistic tracking?
To decide between deterministic and probabilistic tracking, it’s essential to consider your business goals, privacy standards, and the trade-off between precision and audience reach.
Deterministic tracking relies on exact identifiers like email addresses or device IDs, offering unmatched accuracy and reliability. This approach works best when precision is critical, such as in loyalty programs or scenarios demanding strict compliance.
In contrast, probabilistic tracking uses statistical models to piece together anonymized or incomplete data. It’s a better fit for analyzing broader customer trends across devices and channels, especially in environments with tighter privacy restrictions.
Many businesses find value in blending the two methods. Deterministic tracking delivers precise identification, while probabilistic tracking bridges the gaps where deterministic data isn’t available. The best approach depends on your company’s privacy policies, how you interact with customers, and the level of accuracy your marketing efforts require.