

- Secure Infrastructure: Isolate environments (development, testing, production), use VPCs, and enforce strict access controls with IAM and RBAC.
- Credential Management: Avoid hardcoding secrets; rely on tools like AWS Secrets Manager or HashiCorp Vault for secure storage and rotation.
- Data Privacy: Minimize data collection, pseudonymize sensitive information, and ensure encryption at rest and in transit.
- Model Deployment: Use version control, CI/CD pipelines with automated testing, and secure deployment strategies like Blue/Green or Canary.
- Monitoring: Continuously track performance, detect data drift, and implement anomaly detection to catch issues early.
- Compliance: Conduct Data Protection Impact Assessments (DPIA), maintain audit trails, and follow privacy-by-design principles.
This guide ensures your churn models are not just effective but also secure and compliant with regulations.
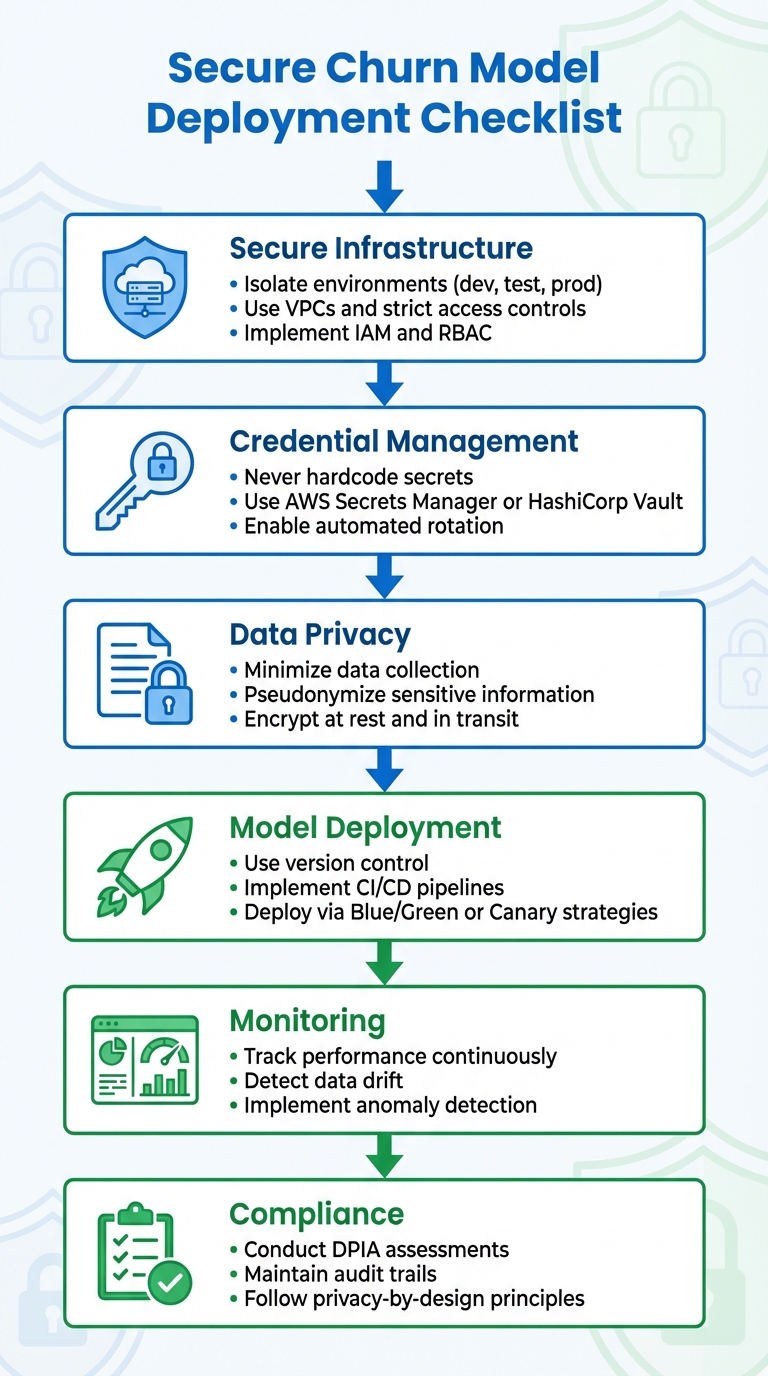
6-Step Secure Churn Model Deployment Checklist
Secure ML Model Deployment for Edge AI Systems
Security Measures Before Deployment
Before rolling out your churn model, it’s critical to secure the environment where it will operate. This step is non-negotiable – it safeguards against unauthorized access and reduces potential risks.
Infrastructure and Environment Security
The first step is to separate your environments completely. Use distinct cloud accounts (e.g., AWS) for experimentation, development, testing, and production purposes. This separation ensures that a security issue in one environment won’t spill over into others. For instance, if credentials are compromised during testing, your production environment remains unaffected.
Next, focus on securing your compute resources. When deploying your model, use containers with distroless images that have minimal capabilities and enforce AppArmor profiles. If you’re working with virtual machines, enable Shielded VMs or confidential computing to protect data during processing. Fine-tune Role-Based Access Control (RBAC) and IAM policies to ensure that training and inference jobs have only the permissions they need – nothing extra.
"A secure ML workflow begins with establishing an isolated compute and network environment." – AWS Security Blog
Place all deployments inside a Virtual Private Cloud (VPC). Strengthen security further by using VPC Service Controls to create a boundary around sensitive customer data. For model artifacts stored in S3, enable versioning and Multi-Factor Authentication (MFA) delete to guard against accidental or malicious deletion.
With the infrastructure secured, the next focus is on managing credentials effectively.
Managing Credentials Securely
One golden rule: never embed database passwords or API keys directly in your source code or notebooks.
"Never hardcode secrets in source code or notebooks. Use secret managers (e.g., AWS Secrets Manager, HashiCorp Vault)." – OWASP
Instead, rely on secret management tools like AWS Secrets Manager, Google Secret Manager, or HashiCorp Vault. These tools encrypt credentials both at rest and in transit and offer APIs with detailed access controls. Set up automated secret rotation to minimize the risk of credential exposure over time.
Whenever possible, eliminate long-term credentials altogether. For example, assign IAM roles directly to compute instances instead of using access keys. In Kubernetes, mount secrets as volumes through the Secrets Store CSI Driver rather than environment variables, which can inadvertently appear in logs.
| Credential Type | Recommended Strategy |
|---|---|
| IAM Access Keys | Use IAM roles assigned to EC2, Lambda, or containers |
| SSH Keys | Replace with AWS Systems Manager or EC2 Instance Connect |
| Database Passwords | Store in secret managers with automated rotation enabled |
| API/OAuth Tokens | Store in secret managers with automated rotation enabled |
Network Security Setup
Once the infrastructure and credentials are secure, network configuration becomes the next priority. Proper network setup ensures that your model is protected from unauthorized access and data breaches.
Start by isolating deployment environments from direct internet access. This limits the risk of malicious software exfiltrating customer data. Use VPC Endpoints or AWS PrivateLink to keep service communications (e.g., S3, CloudWatch) private. Apply endpoint policies to control access based on specific users, actions, and resources.
For Kubernetes deployments, use NetworkPolicies to regulate traffic between pods, ensuring only expected communication occurs. Protect your inference API with a Web Application Firewall (WAF) to block malicious requests and apply rate limiting. Enable VPC Flow Logs to monitor all network traffic and detect anomalies.
Finally, import external libraries into a private repository. This approach maintains development efficiency without exposing your environment to unnecessary risks.
Data Privacy and Compliance Requirements
Once you have a secure infrastructure and credential management in place, the next step is ensuring data privacy and meeting regulatory compliance standards.
Building a churn model means working with sensitive customer data, often subject to strict regulations. By 2025, 75% of the global population will be covered by modern privacy laws. Compliance isn’t optional – it’s a core requirement.
The journey begins with Privacy by Design, a principle outlined in GDPR Article 25. This approach requires embedding data protection into your model architecture right from the start. Technical safeguards like pseudonymization and strong organizational controls should be integrated early on. Conducting a Data Protection Impact Assessment (DPIA) is crucial, especially when working with AI or handling large-scale data processing.
"Privacy by Design GDPR requirements transform this compliance crisis from a reactive firefighting exercise into a proactive framework, embedding data protection into every stage of product development." – Secure Privacy
Another key principle is data minimization – only collect what your churn model absolutely needs. For instance, instead of collecting exact GPS data, rely on broader geographic regions. Additionally, GDPR mandates a clear lawful basis for data collection, requiring "freely given, specific, informed, and unambiguous" consent for activities like behavioral profiling. If your model impacts pricing or service availability, GDPR Article 22 requires human oversight and gives users the "right to explanation".
A staggering 86% of consumers are concerned about how companies use their personal data. To address this, laws like CCPA/CPRA require clear notices about data collection and simple opt-out options. Automating data governance with tools like Amazon Macie can help you scan for personally identifiable information (PII) and manage data retention workflows, ensuring data isn’t kept longer than necessary. Keep detailed audit trails of all data access to demonstrate compliance during regulatory reviews.
Encrypting Data in Transit and at Rest
Encryption is a cornerstone of protecting customer data, even in the event of a breach.
You’ll need two layers of encryption: encryption at rest for stored data (like in S3 or databases) and encryption in transit for data moving across networks.
Opt for Customer Managed Keys (CMK) instead of default provider-managed keys. This ensures you retain control over encryption, meeting GDPR and CCPA standards. Accessing encrypted data should require dual permissions: one for the encryption key and another for the service where the data resides. In distributed training setups, enable inter-container traffic encryption, as communication between compute nodes may otherwise be unencrypted.
"Data encryption can help protect your business data even after a breach occurs. It provides a layer of defense against unintended disclosure." – Kurt Kumar, Amazon Web Services
To enforce encryption, use IAM policies with condition keys like sagemaker:VolumeKmsKey to block resource creation without encryption. Ensure all API requests use HTTPS with TLS. For industries with strict regulations, rely on FIPS 140-2 validated cryptographic modules. Before applying encryption, consider pseudonymizing or de-identifying data to limit exposure of raw PII.
Access Controls and Data Governance
Strong access controls and governance measures are essential for safeguarding sensitive data.
Role-Based Access Control (RBAC) ensures that only authorized individuals can access sensitive datasets or model outputs. Following the principle of least privilege, grant only the permissions necessary for specific tasks.
Classify data based on its sensitivity and criticality to apply appropriate protections. Use separate accounts for experimentation, development, testing, and production environments to prevent cross-environment data leaks. Additionally, disable root access to notebook instances to maintain the integrity of your environment.
Automate PII discovery with tools like Amazon Macie to continuously scan storage buckets. Use managed identities for service authentication, avoiding hardcoded credentials. For critical actions like deleting data, require multi-factor authentication (MFA). Network isolation for algorithm containers can block unauthorized traffic, adding another layer of security.
Implement Service Control Policies (SCP) to set organization-wide permission guardrails. Maintain an inventory of AI assets through automated scanning, which aids in monitoring and incident response. Use VPC Flow Logs to track IP traffic and identify unusual access patterns.
Data Anonymization and Masking
Anonymization and masking techniques help reduce the risk of exposing sensitive customer data by transforming it in ways that prevent direct attribution to individuals.
Leverage AES-256 encryption alongside pseudonymization to replace direct identifiers with artificial values. Techniques like bucketing (e.g., grouping ages into ranges like 25-34 instead of exact ages) or generalization (e.g., using a city name instead of a street address) can minimize raw PII while preserving analytical utility. This approach aligns with GDPR’s data minimization principle while still enabling effective churn prediction.
To prevent your model from unintentionally revealing sensitive information, implement Data Loss Prevention (DLP) controls. Define strict data boundaries using classification and access policies to ensure your model operates within its intended scope. Tag resources with metadata for better governance and auditing.
Model Versioning and Deployment Control
Managing model versions is crucial for deploying models securely and avoiding issues like incorrect releases or delayed rollbacks. Without proper version control, teams can face significant confusion and inefficiencies. A centralized model registry serves as a single source of truth, cataloging each model version along with key metrics and approval statuses. This setup eliminates the chaos of scattered model files and ensures everyone knows which version is currently live.
Setting Up a Model Registry
A model registry simplifies model management by providing full traceability. Each model version should be linked to its source details, including the specific experiment run, code commit, and dataset used during training. When registering a model, attach relevant metadata like accuracy, F1-score, and other performance metrics to that version. For instance, some registries, such as Snowflake‘s, can handle up to 1,000 versions per model, with metadata capped at 100 KB per version.
To ensure smooth transitions through a model’s lifecycle, establish clear staging processes. Models should move through well-defined stages like Development, Staging, and Production, with formal approvals required at each step. Role-Based Access Control (RBAC) is essential here – grant analysts limited USAGE privileges for inference, data scientists READ privileges for metadata access, and reserve full OWNERSHIP rights for senior engineers.
Automate model registration by integrating it into your CI/CD pipeline. Use model aliases, such as @champion or @production, to reference specific versions. This approach makes rollouts and rollbacks easier, as production systems can rely on aliases instead of hardcoded version numbers. Tag each build with a unique ID, code commit hash, and data version to ensure full traceability and meet regulatory standards.
Once version control is in place, the next step is to focus on efficient rollback methods.
Reproducibility and Rollback Plans
When performance dips or a security issue arises, having a plan to revert to a stable model version is critical. Point-in-Time Recovery (PITR) can link your model registry to monitoring systems, enabling automated rollbacks if performance metrics drop below predefined thresholds. Immutable artifact tagging ensures you can identify and trace every component of a model, including the training data version, environment configuration, and dependencies.
Choose a deployment strategy based on your risk tolerance:
| Deployment Strategy | Rollback Speed | Risk Level | Primary Use Case |
|---|---|---|---|
| Blue/Green | Very Fast | Low | Zero-downtime production updates |
| Canary | Fast | Medium | Testing updates on a small portion of live traffic |
| Shadow | N/A (Not live) | Lowest | Testing new versions without impacting users |
Blue/Green deployments allow you to run the old and new models simultaneously, making it easy to switch back if needed with minimal downtime. Canary rollouts involve directing a small percentage of traffic to the new model, monitoring its performance, and gradually increasing traffic if the model performs well. Shadow deployments, on the other hand, run the new model alongside the current production model without affecting real-world decisions, enabling comprehensive testing before full deployment.
To further safeguard production environments, restrict direct write access. All changes should flow through secured CI/CD pipelines with automated testing gates. If a model’s performance on a validation set falls below a set threshold, trigger an automatic rollback to prevent faulty models from affecting users. Additionally, containerizing models ensures that the production environment mirrors the testing environment, reducing the risk of inconsistencies.
These strategies help maintain a secure and reliable deployment process, ensuring your models perform as expected in real-world scenarios.
sbb-itb-2ec70df
CI/CD Pipeline Security
Automated CI/CD pipelines have become a prime target for attackers aiming to inject malicious code. High-profile breaches, such as the Codecov and PHP Git server incidents, highlight how compromised CI/CD systems can silently introduce harmful code into production environments. These incidents stress the importance of securing CI/CD pipelines to safeguard churn prediction model deployments and protect sensitive customer data from unauthorized changes.
Scanning Dependencies and Vulnerabilities
Before anything reaches production, it’s crucial to scan all dependencies for known vulnerabilities. Tools like Software Composition Analysis (SCA) can identify open-source vulnerabilities and licensing issues. For example, malicious versions of widely-used NPM packages like ua-parser-js, coa, and rc have executed harmful code across millions of build environments. This makes dependency scanning a non-negotiable step.
To prevent "Dependency Chain Abuse", use version pinning with lockfiles such as package-lock.json or Pipfile.lock, ensuring dependencies remain immutable. When working with third-party CI/CD actions, pin them to a full-length commit SHA instead of a tag. This prevents backdoor attacks caused by tag manipulation or deletion. Tools like Dependabot can help by monitoring security advisories and automatically raising pull requests when patches are available.
Once dependencies are scanned, the next step is to integrate automated tests to strengthen the pipeline further.
Automated Testing and Security Gates
Static Application Security Testing (SAST) is essential for analyzing source code and identifying vulnerabilities before execution. Additionally, include machine learning-specific tests to ensure data quality, validate feature importance, and confirm algorithmic accuracy.
Security gates should be set up to automatically fail builds if high-severity vulnerabilities are found or if performance benchmarks aren’t met.
"The training and deployment process should be entirely automated to prevent human error and to ensure that build checks are run consistently." – AWS Prescriptive Guidance
Incorporate mandatory code reviews and manual approval steps before deploying any churn model to production. Automated checks, such as data quality tests for schema validation, feature tests to identify unexpected changes, and integration tests for end-to-end functionality, add extra layers of protection. These steps help prevent faulty or compromised models from reaching production.
With testing protocols in place, attention should turn to securing credentials in CI/CD workflows.
Injecting Credentials Securely
Hardcoding credentials in code or configuration files is a risky practice. Instead, leverage secrets management tools like AWS Secrets Manager or HashiCorp Vault.
"Each entity is granted the minimum system resources and authorizations that the entity needs to perform its function." – NIST
This principle can be applied using OpenID Connect (OIDC) to authenticate CI/CD workflows. OIDC provides short-lived, well-scoped access tokens, eliminating the need for long-lived secrets.
To further secure credentials:
- Mask workflow logs to prevent accidental exposure.
- Use intermediate variables for handling secrets.
"The most secure credential is one that you do not have to store, manage, or handle." – AWS Well-Architected Framework
Dynamic secrets that expire immediately after use minimize the risk of exploitation. For any remaining long-lived secrets, configure automated rotation and routinely audit access logs to detect unauthorized attempts. These measures ensure credentials are handled with the highest level of security.
Monitoring and Maintenance After Deployment
Once a model is deployed, the work doesn’t stop. Continuous monitoring is essential to keep it secure and effective. Threats evolve, customer behaviors shift, and data sources change. Without regular oversight, even the most secure deployment can falter or become vulnerable.
Detecting Data Drift and Performance Issues
Data drift happens when the statistical properties of input features change over time, leading to less reliable predictions. This can be especially tricky for churn models since ground truth labels – like whether a customer actually churned – may take weeks or months to arrive.
To combat this, track model quality metrics like Accuracy, Precision, Recall, and F1-score once ground truth data becomes available. Keep an eye on prediction drift by monitoring the distribution of predicted churn scores. If these scores suddenly spike or dip, it’s a sign that something has shifted.
Statistical tests can help monitor feature distributions. Tools like Azure Machine Learning even allow precise calculations of metrics like null value rates, data type errors, and out-of-bounds rates, down to five decimal places.
"When a model becomes stale, its performance can degrade to the point that it fails to add business value or starts to cause serious compliance issues." – Microsoft Azure
Watch for data quality issues by tracking metrics such as Null Value Rate, Data Type Error Rate, and Out-of-Bounds Rate. These checks can catch problems before they affect predictions. For more insight, monitor feature attribution drift using metrics like Normalized Discounted Cumulative Gain (NDCG). This can reveal if the model starts relying on different features than it did during training. Focus on the most important features to reduce noise and save on computational costs.
Use lookback windows to analyze data over meaningful time periods while avoiding overlap between production and reference data. Also, track performance across specific segments – like geographic regions, customer tiers, or device types – to ensure overall metrics aren’t hiding poor performance in key areas. Don’t forget to monitor model age; models that haven’t been retrained in a while are more likely to underperform as environments change.
Anomaly Detection and Incident Response
Beyond data drift, anomaly detection adds another layer of protection. These systems serve as an early warning for potential security breaches or model failures. Effective anomaly detection tracks input distributions, output entropy, latency, and confidence thresholds to flag out-of-distribution inputs or adversarial attacks.
Regularly sample inference data and compare it against training distributions to spot drift. Keep an eye out for numerical stability issues, such as NaN (not a number) or Inf (infinite) values in model weights or outputs.
"Alerting doesn’t mean sending notifications for all possible violations. Instead, it means setting alerts to specific exceptions that are meaningful and important to the development team." – AWS Prescriptive Guidance
Automate alerts through Slack, email, or SMS, but keep them focused on meaningful events to avoid overwhelming the team with unnecessary notifications. Establish clear escalation procedures for handling model drift or abuse. Maintain a versioned model registry to allow quick rollbacks if a breach or significant drift is detected. Some systems even pause updates automatically after repeated failures to prevent further issues.
To minimize risks, deploy models using private endpoints or VPC perimeters to limit traffic exposure. For high-stakes applications, include human reviews of outputs to catch patterns that automated tools might miss.
Logging and Audit Trails
Detailed logs are critical for investigating incidents and staying compliant. Capture logs for all API calls, data access, and modifications to maintain accountability.
Document the full lineage of AI assets, including source code versions, training datasets, hyperparameters, environment configurations, and output artifacts. Store model artifacts in a versioned registry to enable point-in-time recovery and auditing. Use cloud-native audit logging tools to record administrative actions and API calls permanently.
Avoid logging sensitive information, such as personally identifiable information (PII) or confidential data. Use automated tools to mask or redact sensitive fields. For high-volume environments, log a representative sample of request-response pairs to analyze performance and drift regularly.
Monitor system health by tracking operational metrics. For instance, keep disk usage below 75% to ensure smooth data capture. Categorize errors into explicit errors (e.g., HTTP 500s), implicit errors (e.g., incorrect responses), and policy violations (e.g., high latency breaching SLAs).
Consolidate logs into a time-series database for easy integration into dashboards, enabling a clear view of system performance. Compare serving data stats with baseline training data to identify discrepancies, also known as training-serving skew. Maintain "model cards" or documentation linked to specific model versions to clarify their limitations and intended use.
Conclusion
Protecting churn prediction models demands constant attention. Machine learning systems face ever-changing threats, and subtle issues like data drift can gradually weaken a model’s accuracy. Even the most thoughtfully deployed model can become exposed without consistent oversight.
The security measures in this checklist offer multiple layers of protection. As Microsoft’s security team aptly states, "Traditional security practices are more important than ever, especially with the layer of unmitigated vulnerabilities (the data/algo layer) being used between AI and traditional software". These layered approaches provide a strong foundation for safeguarding models at every stage of deployment.
Key practices to prioritize include encrypting data both in transit and at rest, avoiding hardcoded credentials by leveraging secret management tools, and deploying models within isolated VPCs paired with rate-limited APIs. Implement strict Role-Based Access Control and use customer-managed keys through a Key Management Service for direct control over data, offering a "kill switch" for emergencies.
As AI models and their applications evolve, new threats will continue to emerge. Conduct regular security assessments to ensure your defenses keep pace with these changes. Stay vigilant by monitoring for statistical drift, guarding against adversarial attacks, and maintaining comprehensive lineage tracking for all datasets and training workflows.
FAQs
What are the best practices for securely managing credentials during churn model deployment?
To keep credentials safe while deploying churn prediction models, it’s crucial to follow practices that protect sensitive data like API keys, passwords, and tokens. Start by using specialized secret management tools. These tools help you securely store credentials, control who can access them, and automate their rotation, reducing the chances of accidental exposure or misuse.
Adopt the principle of least privilege to limit access – only grant permissions to those who absolutely need them. Keep an eye on access logs to spot any unauthorized or suspicious activity. Never store sensitive information in your source code or unprotected configurations, and always rely on encryption to secure credentials, both when stored and during transmission.
By combining secure tools, strict access policies, and reliable encryption methods, you can effectively lower the chances of credential-related risks in your deployment process.
What steps should I take to comply with data privacy laws when deploying churn models?
To stay compliant with data privacy laws while deploying churn models, it’s crucial to adopt rigorous data governance and security measures that align with regulations like GDPR or CCPA. Start by classifying your data based on its sensitivity, applying role-based access controls (RBAC) to restrict access, and encrypting sensitive information both at rest and in transit.
Collect only the personal data that’s absolutely essential for the model’s purpose, and be transparent with users about how their information is being used. Privacy-protecting methods such as anonymization or pseudonymization can help minimize risks. Regularly auditing your systems, monitoring for vulnerabilities, and acting swiftly in the event of a breach are equally important for maintaining compliance.
Additionally, carefully review the data policies of any third-party tools or services you rely on. Ensure your contracts clearly outline responsibilities for data handling and privacy. By following these steps, you can safeguard user data, meet legal standards, and foster trust in your churn model’s deployment.
How can I monitor and manage data drift in churn prediction models?
To keep a close eye on data drift in churn prediction models, it’s crucial to set up continuous monitoring systems. These systems help track shifts in data distribution that could affect how well your model performs. Leveraging automated tools or frameworks can make it easier to detect changes efficiently. Adding anomaly detection algorithms can also be a game-changer, as they can pick up on subtle shifts in trends or patterns that might otherwise go unnoticed.
If data drift is identified, act quickly. Options include retraining the model with fresh data or fine-tuning it to reflect the new patterns. Consistently reviewing performance metrics ensures your model remains in sync with changing customer behaviors and business demands.