

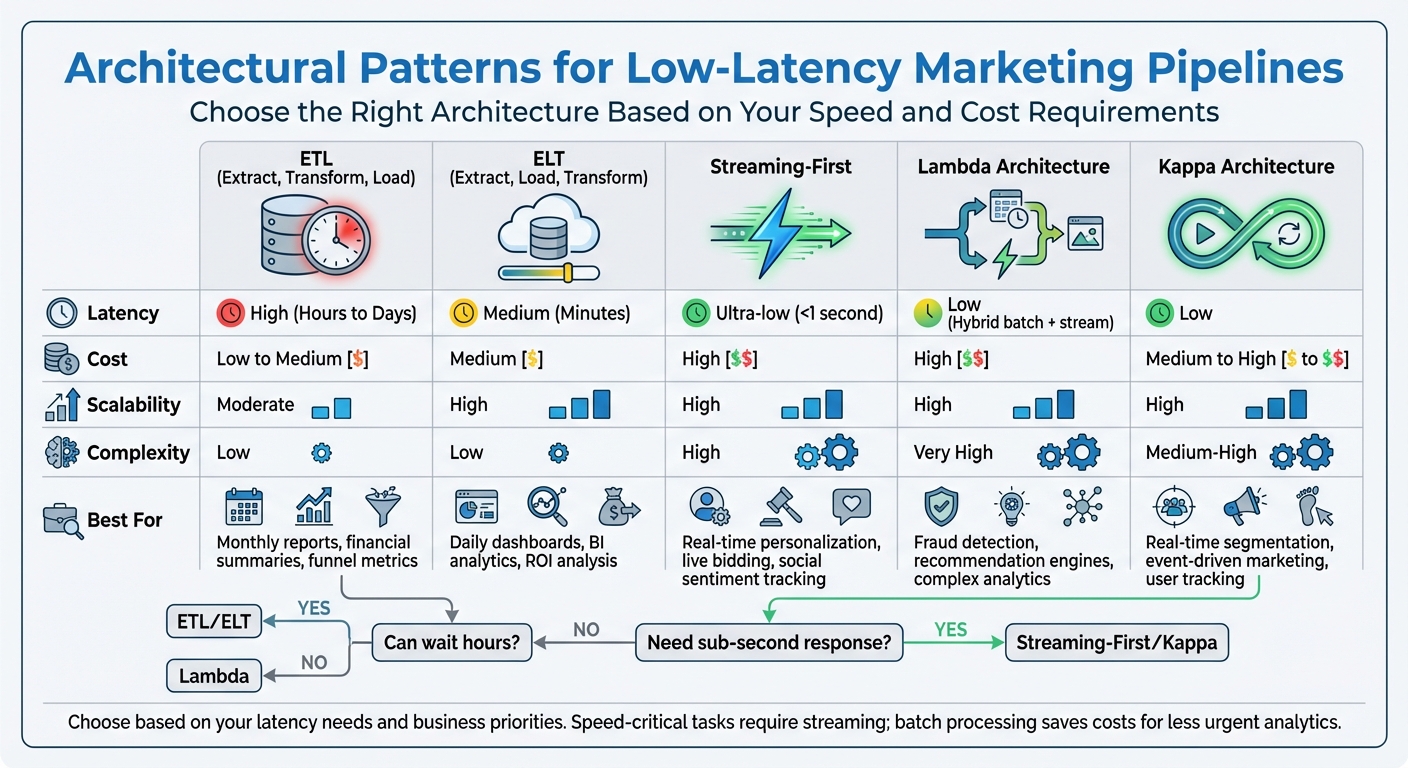
In marketing, speed can make or break your campaigns. Data pipelines that process information in real time are essential for tasks like personalized recommendations, live campaign adjustments, and fraud detection. But not all architectures are built the same. Here’s a quick breakdown of five common approaches:
- ETL (Extract, Transform, Load): Processes data in batches, suitable for tasks like monthly reports but too slow for real-time needs.
- ELT (Extract, Load, Transform): Loads raw data first, then processes it in the cloud, offering faster results for tasks like daily dashboards.
- Streaming-First: Handles data continuously, delivering sub-second latency for time-sensitive tasks like real-time bidding.
- Lambda Architecture: Combines batch and streaming pipelines for both accuracy and speed but requires maintaining two systems.
- Kappa Architecture: Focuses on continuous streams, using a single pipeline for both real-time and historical data.
Each approach has trade-offs in latency, cost, scalability, and complexity. For instance, ETL is cost-efficient but slow, while Streaming-First delivers speed at a higher cost and complexity. The right choice depends on your marketing goals and how quickly you need to act on data.
Quick Comparison
| Pattern | Latency | Cost | Scalability | Complexity | Best For |
|---|---|---|---|---|---|
| ETL | High (Hours) | Low to Medium | Moderate | Low | Monthly reports, financial summaries |
| ELT | Medium | Medium | High | Low | Daily dashboards, raw data analysis |
| Streaming-First | Ultra-low | High | High | High | Real-time personalization, live bidding |
| Lambda | Low (Hybrid) | High | High | Very High | Fraud detection, recommendation engines |
| Kappa | Low | Medium to High | High | Medium-High | Real-time segmentation, user tracking |
The bottom line? If speed is critical, Streaming-First or Kappa is your best bet. For less urgent tasks, ETL or ELT can save costs. Choose based on your latency needs and business priorities.
Comparison of 5 Marketing Data Pipeline Architectures: Latency, Cost, and Use Cases
Real Time Data Pipelines | Data Engineering
1. ETL Architecture
ETL, which stands for Extract, Transform, Load, is a traditional method for building data pipelines. It works by extracting data from source systems, transforming it on a staging server outside the data warehouse, and then loading the cleaned, processed data into the destination. This step-by-step method is effective for structured and predictable workflows, but it does come with some built-in limitations, especially when it comes to speed.
Latency
ETL operates in batch mode, meaning it processes data at set intervals. These intervals can range from minutes to hours. While this might be fine for some use cases, it’s far from ideal for marketing scenarios that require instant responses. One of the reasons for this delay is that ETL engines lack record-tracking capabilities, which often forces them to reprocess entire datasets, adding even more time to the process.
AppsFlyer’s experience highlights this challenge. As the company scaled to cover 95% of mobile devices globally, their in-house ETL tool became a constant source of frustration. Schema changes demanded ongoing engineering efforts, and a single analytics use case ended up costing over $1.1 million annually.
Cost
Maintaining a legacy ETL platform can be resource-intensive, often requiring a team of 30–50 engineers. Newer, serverless solutions like AWS Glue can reduce costs by charging only for the compute time used during transformations. However, while ETL can sometimes be cheaper than real-time streaming for workloads that aren’t time-sensitive, the upfront planning and ongoing maintenance can lead to hidden expenses.
For example, PowerLinks, a programmatic ad marketplace, managed to slash its monthly infrastructure costs from over $200,000 to just $8,000–$10,000 by moving away from a high-maintenance ETL setup. These cost considerations become even more pressing as data volumes grow.
Scalability
As data volumes increase, the transformation layer in ETL pipelines can become a bottleneck. One major issue is schema drift – when changes in the source data break pipelines, requiring manual intervention to fix them.
Avner Livne, Real-Time Application Groups Lead at AppsFlyer, summed up the challenge:
Data transformation was very hard. Schema changes were very hard. While [the system] was functional, everything required a lot of attention and engineering.
Another limitation is that ETL often overwrites records with the latest state, which can result in losing valuable historical context. These scalability challenges make ETL less suitable for dynamic, fast-changing environments.
Marketing Use Case Fit
ETL is a good fit for tasks that aren’t time-sensitive, like generating monthly attribution models, conducting long-term trend analyses, or running overnight batch jobs that need to be ready by 9:00 AM. It’s also ideal when the destination system, such as Salesforce or Stripe, has strict schema requirements and can’t handle malformed data.
However, if your marketing strategy depends on real-time personalization or instant fraud detection, ETL’s batch processing cycles can cause delays that result in missed opportunities. For instance, by the time the data is processed and ready, you may have already lost a customer’s attention.
This wraps up the ETL overview and leads us into architectures that bring processing closer to the data store.
2. ELT Architecture
ELT flips the script on the traditional ETL process by loading raw data directly into a cloud warehouse and then transforming it right there. Unlike ETL, which relies on batch processing, ELT ingests raw data directly, sidestepping many of the latency and resource limitations associated with older methods. By using the elastic computing power of cloud platforms like Snowflake, BigQuery, or Redshift, ELT eliminates hardware restrictions, enabling faster and more adaptable data processing.
Latency
One of the standout features of ELT is its ability to reduce latency by running transformations within the warehouse itself. Instead of waiting for a separate staging server to handle processing, ELT kicks off event-driven triggers (like S3 notifications) to start serverless transformations as soon as fresh data arrives. This setup supports sub-minute latency, making real-time dashboards a reality. As Jim Kutz, a Data Analytics Expert, puts it:
"By loading raw data first and transforming it inside the warehouse, you tap into elastic compute for faster parallel processing and avoid the fixed capacity limits that slow classic ETL pipelines."
Another benefit of ELT is its schema-on-read capability. Raw data is available for querying almost immediately, giving analysts the freedom to refine datasets as business needs evolve. This flexibility eliminates the need to overhaul rigid pipelines and can lead to savings in processing time and costs.
Cost
The pay-as-you-go pricing model of ELT offers a cost advantage over traditional ETL setups, which often require dedicated servers that may sit idle for most of the day. For example, running ETL jobs on EC2 instances for just a few hours daily can cost around $2,000 per month. In contrast, serverless ELT architectures scale down to zero when idle, charging only for active compute time.
That said, sudden traffic spikes can lead to an unexpected increase in costs due to excessive concurrent functions. To avoid this, teams should set limits on concurrency for serverless functions and monitor warehouse usage carefully. Additionally, adopting columnar data formats like Parquet or ORC can improve data compression, while using S3 Bucket Keys can reduce AWS KMS encryption expenses by up to 99%.
Scalability
Cloud warehouses excel in ELT workflows because they separate storage from compute, allowing each to scale independently. Raw data is stored in its original state (often called the "Bronze" layer), making it easy to reprocess, debug, or enhance without starting from scratch. For instance, in 2025, the Brazilian food tech company Liv Up transitioned to an ELT framework using Stitch to integrate data from MongoDB, Google Analytics, and Zendesk. This shift replaced a labor-intensive manual process, cutting extraction and loading time by 8 hours per week. The result? Faster access to business intelligence through direct BI tool queries on raw warehouse data.
However, ELT does have its challenges. For example, simple models that overwrite records with the latest data can lose historical details, such as tracking how a lead progresses through a sales funnel. To address this, teams can implement strategies like event-driven pipelines or Slowly Changing Dimensions (SCD). Additionally, monitoring data quality remains crucial to ensure reliable outcomes.
Marketing Use Case Fit
ELT is particularly effective for marketing workflows that handle high-speed data streams, such as social media feeds, clickstream events, and point-of-sale transactions. It allows analysts to quickly generate sales roll-ups and query raw data directly, even when dealing with semi-structured formats like JSON logs. For teams producing daily marketing reports or creating customer segments, ELT strikes a great balance between speed and cost.
However, if your use case demands instant responses – like fraud detection or real-time personalization – ELT alone may not be enough. In such scenarios, integrating streaming-first solutions alongside your ELT setup can provide the level of immediacy required.
3. Streaming-First Architecture
A streaming-first architecture goes beyond the capabilities of ELT by eliminating batch processing altogether, opting instead for continuous real-time data handling. This approach uses a publish/subscribe model to process incoming data streams as they arrive. It relies on five key components: data sources (like IoT devices or mobile apps), stream ingestion (via producers or SDKs), stream storage (such as Amazon Kinesis or MSK), stream processing tools (e.g., Apache Flink or Kafka Streams), and destinations (like S3, Redshift, or OpenSearch). By replacing batch-based methods with continuous processing, this architecture delivers the real-time responsiveness that modern marketing demands.
Latency
Streaming-first architectures are designed for lightning-fast processing, achieving sub-second speeds that enable real-time decision-making. For instance, tools like Apache Flink and Kafka Streams can process individual records in under a second, while Amazon Kinesis Data Streams boasts latencies as low as 70 milliseconds with features like Enhanced Fan Out. This level of speed is critical in marketing, as highlighted in an AWS Whitepaper:
The customer’s attention will be lost if these recommendations are not available for days, hours, or even minutes – they need to happen in near real-time.
In comparison, traditional methods such as AWS Lambda or the Kinesis Client Library often result in latencies measured in seconds.
Cost
Streaming services typically charge based on throughput, meaning costs are tied to the volume of active data being processed. For example, Kinesis Data Streams On-Demand, Amazon MSK Serverless, and Managed Flink all follow this pricing model. To save on costs, strategies like using Spot Instances or dynamic partitioning (e.g., grouping data by customer IDs before storing it in a data lake) can be employed.
Scalability
Scalability is a strong suit of streaming architectures. Systems like Apache Kafka (or MSK) use partitioning, while services like Kinesis rely on sharding to handle increases in throughput. Adding more partitions or shards allows for parallel processing across multiple consumers. For example, Kinesis can scale in seconds with a single click, whereas managed Kafka services like MSK might take a few minutes. Additionally, services such as Cloud Run can rapidly scale from zero to 1,000 container instances as needed. This architecture also decouples data producers from consumers, enabling multiple applications to operate on the same data stream simultaneously – such as one application powering live dashboards and another managing archival storage.
Complexity
While streaming pipelines offer impressive capabilities, they often require more technical expertise compared to batch processing. However, managed services have made this process easier. For simpler use cases, no-code tools like BigQuery subscriptions for Pub/Sub can directly feed data into a warehouse. On the other hand, advanced features like exactly-once processing (crucial for accurate marketing attribution) demand more sophisticated frameworks like Apache Flink or Kafka Streams, which natively support such functionality – something standard AWS Lambda implementations lack. Breaking down processing into smaller, distinct tasks (e.g., aggregation and downstream writing) can help simplify tuning and isolate potential failures.
Marketing Use Case Fit
Thanks to its low latency and scalability, a streaming-first architecture is ideal for time-sensitive marketing tasks. For instance, real-time bidding (RTB) systems in programmatic advertising rely on streaming to handle bid requests and responses, ensuring budgets are updated and bid signals are optimized instantly. Clickstream analytics benefit from real-time processing of user navigation patterns, allowing marketers to adjust campaigns during live events or product launches. Fraud detection systems use streaming to analyze transactions on a click-by-click basis, identifying suspicious behavior or fake accounts as they occur. In video streaming advertising, pipelines often aim for reporting latencies of just one to two seconds to keep up with continuously updated data. However, for tasks that can tolerate delays – like generating daily marketing reports or analyzing historical trends – batch processing or ELT may be more cost-efficient.
sbb-itb-2ec70df
4. Lambda Architecture
Lambda Architecture handles data by using both batch and streaming pipelines, striking a balance between accuracy and speed. It’s structured into three main layers: the Batch Layer, which recalculates views from an unchanging master dataset to ensure precision; the Speed Layer, which processes real-time data streams to reduce delays; and the Serving Layer, which combines the outputs of the two layers to answer queries effectively. By integrating immediate insights with detailed historical data, this design addresses latency and scalability challenges while paving the way for exploring alternative approaches.
Latency
The Speed Layer is designed for real-time data processing, making information instantly available for queries. In contrast, the Batch Layer typically updates less frequently, often once or twice a day. This setup allows marketers to act quickly on time-sensitive tasks, like adjusting bids during an active campaign, while still maintaining the high level of accuracy needed for activities like billing and reporting.
Cost
Operating both batch and speed layers comes with added expenses since data is processed twice – once for immediate insights and again for long-term accuracy. Unlike single-pipeline systems, Lambda Architecture requires separate resources for each layer. The Batch Layer tends to have higher costs due to the storage and compute power needed for complete recomputations, while the Speed Layer demands high-speed, low-latency processing. For example, AWS Lambda, a popular tool for Speed Layer processing, charges about $0.20 per 1 million requests beyond its free tier.
Scalability
Lambda Architecture’s distributed design allows it to scale efficiently, especially when paired with cloud-based storage and serverless solutions. The Batch Layer can handle vast historical datasets using platforms like Hadoop, Snowflake, or BigQuery. Meanwhile, the Speed Layer manages real-time data with tools like Kafka, Flink, or Spark Streaming. However, AWS Lambda functions have a runtime limit of 900 seconds, making them unsuitable for lengthy batch jobs without additional orchestration.
Complexity
One of the main challenges of Lambda Architecture is the duplication of processing logic. Maintaining separate logic for batch and streaming layers adds complexity. Synchronizing the results from both layers can be tricky, and reorganizing or migrating data within this dual-layer system often requires significant effort.
Marketing Use Case Fit
Lambda Architecture is particularly effective for applications requiring both real-time responsiveness and long-term accuracy. For instance, it’s ideal for programmatic advertising and real-time bidding (RTB), where immediate decisions are critical, but accurate historical records are essential for billing and analysis. It also works well for clickstream analytics in e-commerce, enabling real-time tracking of user actions to trigger timely marketing responses, with later reconciliation for deeper insights. Additionally, fraud detection systems can take advantage of the Speed Layer to flag suspicious activities immediately, while the Batch Layer refines fraud models over time. For those seeking a simpler, unified approach, the next section delves into Kappa Architecture.
5. Kappa Architecture
Kappa Architecture simplifies data processing by removing the batch layer, treating all data as a continuous stream. When historical data needs to be reprocessed – due to code updates or changing business logic – events are replayed from an immutable log (like Apache Kafka) through the same pipeline. Let’s dive into its latency, cost, scalability, complexity, and its fit for marketing use cases.
Latency
Kappa Architecture processes events the moment they arrive, ensuring consistently low latency. For example, Netflix uses this approach to power its recommendation engine, enabling content suggestions to reflect a user’s latest activity within seconds. Similarly, Spotify employs this architecture for real-time ad delivery, ensuring advertising and recommendations adapt instantly to user behavior.
Cost
By relying on a single technology stack, Kappa reduces infrastructure costs. However, storing long-term event streams, such as in Kafka, can lead to ongoing storage expenses. Replaying large historical logs also requires significant computational power. That said, managing one unified codebase often offsets these costs, especially with cloud-native solutions that allow resources to scale dynamically as needed.
Scalability
Kappa Architecture scales horizontally by distributing workloads across multiple nodes using tools like Apache Kafka, Flink, or Samza. A notable example is Uber, which utilizes Kappa to run a sessionization pipeline for dynamic pricing. Their setup operates on 75 cores with 1.2 terabytes of memory and processes backfills of approximately 10 terabytes of data from Hive – all using the same cluster configuration. While stateless operations scale effortlessly, stateful tasks, such as windowed aggregations, require careful resource allocation.
Complexity
One of Kappa’s strengths lies in its simplicity. By consolidating everything into a single codebase, it avoids the operational challenges of maintaining separate pipelines, as seen in Lambda Architecture. As Rajesh Rajagopalan (Learner for Life) puts it:
The basic idea was to get rid of the batch layer, and use stream data processing for both historical/static data and live/streaming data.
For example, Pinterest uses Kappa to track real-time user actions – like pins, repins, and clicks – keeping analytics dashboards and recommendation engines continuously updated. However, teams need strong expertise in stream processing, and they must ensure the processing logic is idempotent to prevent duplicate events during retries.
Marketing Use Case Fit
Kappa Architecture shines in scenarios where data value diminishes quickly. Real-time personalization benefits immensely, as marketers can act on a user’s current session data instead of relying on outdated batch aggregates. This can significantly improve conversion rates. Continuous customer segmentation also enables highly targeted "segment-of-one" marketing, ensuring user profiles stay current. Additionally, instant campaign monitoring provides real-time insights into clickstreams, ad impressions, and conversions, allowing marketers to adjust strategies on the fly. Uber’s implementation, which models Hive tables as streaming sources, illustrates how real-time updates – like pricing adjustments and driver dispatch improvements – can coexist with backfilling data for late-arriving events.
Strengths and Weaknesses
Architectural patterns often involve trade-offs between latency, cost, scalability, and complexity. Let’s break down how some of the most common patterns stack up.
ETL is a reliable choice when data quality outweighs speed, such as with monthly funnel metrics or financial reconciliation. However, its high latency – ranging from hours to days – makes it unsuitable for real-time applications like live campaigns.
ELT has become the go-to for cloud-native environments, offering high scalability and flexibility at a moderate cost. It’s ideal for BI dashboards or ROI analysis. The catch? Without proper governance, raw data can quickly spiral into an unmanageable overload.
Streaming-First architectures excel in scenarios requiring ultra-low latency – think under one second. This makes them perfect for real-time personalization or tracking live social sentiment. But this speed comes at a price: higher infrastructure costs and the need for advanced engineering expertise. As Striim aptly puts it:
Where batch ETL answers the question, ‘What happened yesterday?’, streaming pipelines answer, ‘What is happening right now?’
Lambda Architecture combines the strengths of both batch and real-time layers, offering historical accuracy alongside real-time speed. This hybrid approach works well for complex tasks like recommendation engines or fraud detection, where precision is key. The downside? Maintaining two separate codebases significantly increases both development and maintenance workloads.
For teams looking to avoid the complexity of dual layers, Kappa Architecture provides a streamlined alternative. It uses a single streaming layer for both real-time and historical data via event replay, which simplifies development while keeping latency low. However, reprocessing large historical datasets can be computationally intensive, and the approach demands strong expertise in stream processing to avoid duplicate operations.
Here’s a quick comparison of these patterns and their trade-offs:
| Pattern | Latency | Cost | Scalability | Complexity | Marketing Use Case Fit |
|---|---|---|---|---|---|
| ETL | High (Hours/Days) | Low to Medium | Moderate | Low | Monthly funnel metrics, financial reconciliation |
| ELT | Medium (Minutes) | Medium | High | Low | General marketing analytics, BI dashboards |
| Streaming-First | Ultra-low (<1s) | High | High | High | Real-time personalization, live social sentiment |
| Lambda | Low (Hybrid) | High | High | Very High | Complex recommendation engines, fraud detection |
| Kappa | Low | Medium to High | High | Medium-High | Event-driven marketing, real-time user segmentation |
Conclusion
In marketing analytics, the architecture of your data pipeline plays a critical role in determining how quickly you can respond to campaigns and how effectively you can maximize ROI. The right choice hinges on your latency requirements and the impact on your business goals. For tasks like real-time personalization or fraud detection, Streaming-First or Kappa architectures are ideal, offering sub-second responsiveness. As AWS highlights:
Response time has a huge impact on conversion rate in advertising, it is important for advertisers to respond as quickly as possible.
On the other hand, for tasks like weekly performance reports or monthly funnel analysis, batch processing using ETL or ELT methods is more cost-efficient while still delivering high-quality insights. Striking this balance is key to deciding whether to invest in streaming technologies or stick with batch processing.
Kappa Architecture stands out for its ability to handle real-time data with a single codebase, eliminating the need for dual processing layers. By replaying immutable logs, it maintains low latency, though reprocessing costs can be higher. For marketing scenarios such as event-driven segmentation or real-time user tracking, these costs are often manageable and worthwhile.
However, not every organization needs lightning-fast streaming capabilities. The global data pipeline market is expected to hit $43.61 billion by 2032, but investing in streaming infrastructure isn’t always necessary. Instead, align your latency requirements with your marketing objectives. Use streaming for live campaign adjustments, and rely on batch processing for tasks where precision outweighs speed, such as financial reconciliations.
For companies with limited resources, it’s important to take a gradual approach. ELT is often the best starting point, as it utilizes the computational power of cloud data warehouses, preserves raw data for future needs, and integrates seamlessly with modern BI tools. Once your analytics foundation is solid, you can introduce streaming for specific, high-priority use cases.
The key is to let your business needs guide your technology choices. Determine where speed is critical and where delays are acceptable, and design your pipeline architecture accordingly. This thoughtful approach ensures a balance between performance and cost efficiency, aligning perfectly with the strategies discussed above.
FAQs
What’s the difference between Streaming-First and Kappa Architecture in low-latency pipelines?
The main distinction between Streaming-First and Kappa Architecture lies in their approach to data processing and system design. Streaming-First combines real-time and batch processing, often relying on multiple systems or layers to handle different data types. While this allows for greater flexibility, it can also add layers of complexity to the overall system.
In contrast, Kappa Architecture takes a more streamlined approach by treating all data as streams. It leverages a single stream processing engine for both real-time and historical data, eliminating the need for separate batch and speed layers. This reduces code duplication and simplifies the architecture. Essentially, Streaming-First is a broader concept, whereas Kappa Architecture focuses on a unified, streamlined method for handling data streaming.
How does the architecture of a data pipeline affect the responsiveness of marketing campaigns?
The design of a data pipeline is a key factor in determining how swiftly marketing campaigns can react to real-time events. Low-latency pipelines are built to process and deliver data with minimal delays, making it possible to take timely actions like sending personalized offers, engaging with customers instantly, or detecting fraud as it happens. These systems ensure data moves quickly and smoothly from various sources, allowing marketing platforms to adjust to customer behavior or market shifts almost immediately.
Architectures that emphasize low latency, scalability, and resilience – such as distributed streaming systems or scalable data warehouses – play a major role in managing large data volumes and meeting user demands. Tools like Apache Kafka and Amazon Kinesis are excellent for capturing and processing real-time data, helping campaigns stay relevant and actionable. Selecting the right architecture ensures marketing strategies remain flexible, effective, and ready to deliver meaningful results.
What are the benefits of choosing ELT instead of ETL for a data pipeline?
Choosing ELT (Extract, Load, Transform) instead of ETL (Extract, Transform, Load) brings several advantages for businesses navigating today’s data-driven world. In the ELT process, raw data is loaded directly into the data warehouse first, with transformations happening afterward. This method works especially well in cloud-based environments, where the immense scalability and processing power of modern platforms can manage large volumes of raw data with ease.
One major perk of ELT is its flexibility. Since transformations occur within the data warehouse, teams can adjust and refine their processes as business needs evolve – no need to redo everything from scratch. Plus, it’s often more cost- and time-efficient for handling complex datasets. By skipping extensive pre-processing, ELT taps into the capabilities of advanced data warehouses to handle transformations, saving both effort and resources.